[In July 2023, Kim Wuyts and Isabel Barbera invited me to present the keynote talk to the International Workshop on Privacy Engineering in Delft, Netherlands. Subsequent to that, and because we felt there wouldn’t be an overlapping audience, Nandita Narla and Nikita Samarin, invited me to give the same talk to another group of privacy engineers at the PEP23 workshop ahead of SOUPS in Anaheim, CA. For those who couldn’t be there at either event, I decided to write this blog post to summarize my talk.]
In September of 2013, I authored a blog post for the International Association of Privacy Professionals entitled “Is 2013 the year of the privacy engineer?” The post came after myself and Stuart Shapiro provided two early workshops on privacy engineering to crowds at IAPP conferences that year and just months before our seminal paper on Privacy Engineering co-authored with, at the time, Information and Privacy Commissioner of Ontario Canada, Ann Cavoukian. The IAPP blog laid out a basic argument that addressing privacy issues needed to move out of legal departments and into engineering. Clearly, my prognostication was premature as to actual industry action, which still prefers legal solutions over technical ones. What about 2023, though? Is it finally time for the ascendence of the privacy engineer?

Before we can answer this question, we need to explore a bit about the concept of privacy engineering. Just a few weeks ago the IAPP published an infographic “Defining Privacy Engineering.”
The publication was the culmination of my push, while a member of the IAPP’s Privacy Engineering Advisory Board, to advocate for rigorous construction of the field. My concern was the term being diluted and applied to anything “technical” in the field of privacy. Anecdotal evidence suggested many lawyers and privacy analysts were deeming any type of coding or technical implementation as “engineering.” This led to bloggers and journalists also applying the engineering moniker to those doing the technical aspects of privacy based on what they were learning from the privacy professionals of the day.
A feedback loop ensued! Privacy professionals reading those blogs and articles similarly referred to technical privacy folks as engineers. Even those doing technical work started referring to themselves as privacy engineers, a form of self-selection bias, which only added fuel to the cycle. Of course, compounding this are job descriptions, which, despite being labeled as “privacy engineer” could just as easily fall under the title of “analyst,” “technologist” or some other non-engineering role. During my exploration of this topic, I found that HR departments at large not-to-be-named tech companies often require the engineering department to hire an “engineer” thus leading to an explosion of engineering roles with no engineering duties (“public relations engineer”, “finance engineer”, etc.)
This debate (“who is the true engineer”) that I’m putting forward is reminiscent of one from my childhood, the question of who is a punk and who is a poseur (aka, a suburbanite who spikes their hair on the weekends but doesn’t live the lifestyle of punk). Though I don’t recall the intensity of the debate at that time, in 1985 MTV (back when they played music and not 24 hours of Ridiculousness) put out a documentary on the LA punk scene entitled “Punks & Poseurs” which suggested the question was one of massive scrutiny within the subculture.

Lest you think the punk/privacy connection is fleeting, I present exhibit two into evidence: the color similarities of the album cover for the Exploited’s Punks Not Dead and CMU’s privacy engineering program logo “Privacy is Not Dead.”

While I don’t think any privacy engineers are going around beating up faux privacy engineers, the debate is worth having, in my opinion, and potentially more important to those relying on the services of such engineers. So let’s stage dive into the discussion:
What is Engineering?
There are a few authoritative definitions of engineering, but I like this one from the Accreditation Board for Engineering and Technology: “The profession in which a knowledge of the mathematical or physical sciences gained by study, experience and practice is applied with judgement to develop ways to utilize, economically, the materials and forces of nature for the benefit of mankind.” Applying this to privacy, it seems fairly logical that privacy takes the role of the “benefit of mankind.” I think the primary gist of what distinguishes an engineer from say an analyst or other professional working in the area is the application of knowledge of mathematical or physical sciences.
I’d like to analogize this to bridge building. You can design and build a bridge without “engineering” that bridge. However, you may end up with a bridge that collapses, as the Tacoma Narrows Bridge did in 1940. In response, a builder could naively suggest a stronger bridge, better materials, or more pillars, but it takes the analysis of an engineer, applying the mathematical and physical sciences, to determine the problem of aerolastic flutter and engineer a solution.


Another analogy I like comes from the realm of software engineering. Programming students are often given the task of sorting lists. Invariably, they produce a sorting program that compares all elements of the lists to every other element. Those who have more study in proper design of sorting algorithms know that this is inefficient, requiring, at worst, n times n passes (where n is the number of elements on the list). More efficient sorting algorithms exist such as “merge sort.” Other sorting algorithms can take advantage of qualities of the elements being sorted to be even more efficient. These are often described using big O notation, where O means on the order of. Inefficient algorithms, as just described, are usual O(n2) and more efficient ones are O(n log n). Hence, the study of big O notation and algorithms distinguishes the engineering of software versus the programming of software. Both an engineer and a programmer may write software to result in sorting a list, but the engineer has developed a more efficient program by applying the study of mathematics and science to optimize the resources of the computer.

Unlike bridge engineering or software engineering, privacy engineering actually encompasses several different domains. In this way, it’s more similar to, say, safety engineering, where the quality being achieved (safety or privacy) can be desired in many distinct applications.
We can think about safety as a desired quality in the aforementioned bridge engineering, but also in industrial machine design, tool safety, food handling equipment, medical equipment, and many other fields. Someone designing safety into a bridge will not use the same skills and resources as someone building safety in food handling, though they will still have the generic application of math and science to solving the problem. Similarly, privacy engineering is an umbrella covering different disciplines. As part of the aforementioned attempt by the IAPP to define privacy engineering, the advisory board identified a non-exhaustive set of domains where you might apply different engineering techniques to build in privacy.
Software Engineering: This is what most people think about when thinking of privacy engineering. Software engineering covers the design and development of software and building in privacy during the collection, processing and sharing of data. The engineering comes into play during considerations of the tradeoffs of efficiency, utility and risks to individuals.
IT Architecture: When you combine multiple IT components (which may be software engineered), you may get emergent properties or exacerbate risks that were negligible in their individual components. IT Architecture includes considerations of protocols and interfaces between components, again optimizing between efficiency, utility and risks.
Data Science: Privacy in data science concerns the risks from data sets, combinations of data, inferences and such without consideration of the specifics of software collecting, processing or sharing that data. Data science for privacy often involves investigating identifiability of data or linkability between data sets.
HCI/UI-UX: It’s not all about the data. Many privacy harms occur during the interactions between individuals and computers. Spam, pop-up ads and other intrusions are a form of invasions into ones personal space. Manipulative designs may interfere with individuals’ autonomy and decision making. The study of Human Computer Interactions can make use of behavioral economics, psychology and other scientific analysis to minimize these privacy harms.
Business Processing Engineering: Business process engineering traditionally covers the design of efficient business processes. Think industrial manufacturing, though it can be applied to more white-collar business processes like HR and Marketing. While efficiency of resources is the primary goal of business processes, they can be designed to improve privacy as well. This is a nascent area of development, but one worth watching.
Physical Engineering: While there are few, if any, self-identified privacy engineers working in physical spaces, privacy has been a design consideration in the physical world for as long as there have been eaves to stand under. Not only in private spaces in homes, but hospitals are also a frequent target for privacy design. But what about engineering? There is increasing opportunity for physical engineering for privacy in regard to IOT devices, both in their design and the design of spaces to prevent ubiquitous surveillance by those devices.
Systems Engineering: This is my primary area of work. Systems engineering considers the interconnectedness of all of the above: cyber-physical-social systems and the interactions and interfaces between them and individuals. Systems engineering looks at narrow risks, risk from emergent properties, cascading risks between system elements and tradeoffs of privacy with other quality and functional system requirements.
Next Steps for Privacy Engineering
As you can see, privacy engineering covers a wide swath of different domains. Besides the generic desire for more privacy, what cross-discipline language can we seek to define similarities? I think we can draw upon the analogous safety engineering for guidance. What are safety engineers trying to do? They are attempting to reduce risk, to make products or service safer by reducing the likelihood of harmful events and the level of harm when those events occur. Similarly, privacy engineers need to focus on reducing privacy risk, the likelihood of privacy events and impacts of those events. [Note, if you’re thinking data breaches, you and I need to have a talk. Privacy is not security, but I won’t derail this blog post with a privacy versus security risks deep dive.]
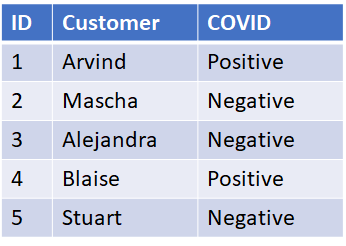
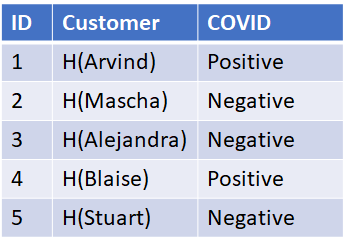
Privacy risk research is still in its early development. Significant research still needs to be done into quantifying privacy risk, creating feedback loops to incorporate real world data back into risk analysis, measuring the effectiveness of controls on risk and producing ways of determining reasonable levels of risk tolerance. In addition there needs to be more work to tie controls to risk. Privacy professionals have worked for years at developing various technical and organizational controls meant to improve privacy. However, scant work has been done to tie those controls to actual risk reduction. It’s as if bridge engineers said using high-tensile steel improves bridge safety and had tons of data and science backing up the resilience and breakpoints of the steel. That statement seems logical but lacks measurable risk reduction. While you may measure the tensile strength of the steel, that’s different than measuring use of that steel in a particular design’s effect on risk. Similarly, there are many measures, metrics and KPIs for privacy, but what does the ε in differential privacy translate into as to whether a real threat actor is likely to attempt to re-identify the patient in a doctors office’s prescription for 325 mg of acetaminophen?
There also needs to be a causal connection between controls and risk reduction. Increasing the tensile strength of the steel in a bridge isn’t going to reduce risk if the weak point is the connection to the earth. Bridging this gap is what the Institute of Operational Privacy Design (IOPD) is working on in our newest standard. The IOPD is attempting to use structured assurance cases, something used in safety engineering, in privacy. The idea is that you state a claim, such as “This privacy risk has been mitigated” then make an argument as to why it should be considered mitigated. Finally, you provide evidence to support this argument. Lawyers should like this, because it’s similar to a legal argument, showing why some evidence supports some legal claim.