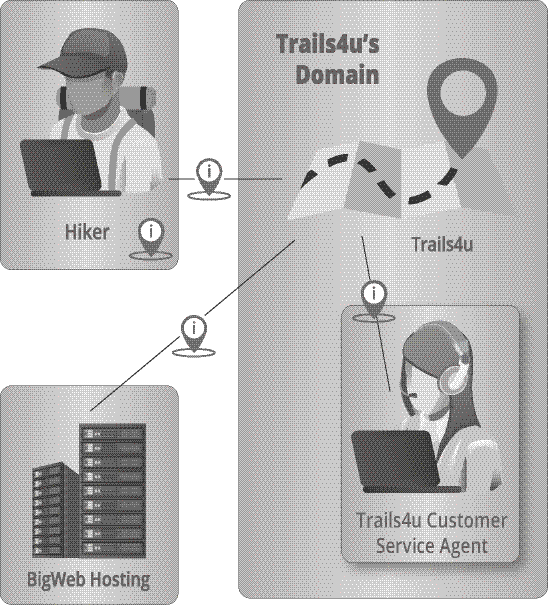
For those that don’t know, I’m an avid hiker and biker. In fact, I’m currently undertaking a challenge that I created for myself to do 90 different trails in 100 days. Currently, I’m 2/3rds through that challenge with ~30 days to go. One of the keys tools I use for finding and following trails is a mobile App called AllTrails.
I’ve used it for years but now I’m using it daily. While I’ve known that trail apps have potential privacy problems (I even included building a privacy friendly trail app as an example in my book, see illustration), my recent use has pinpointed how problematic.
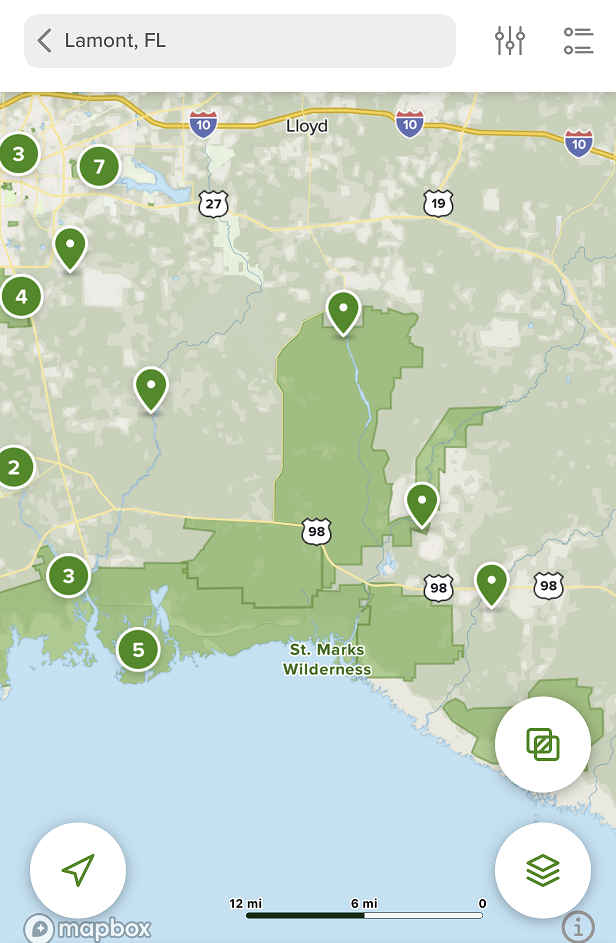
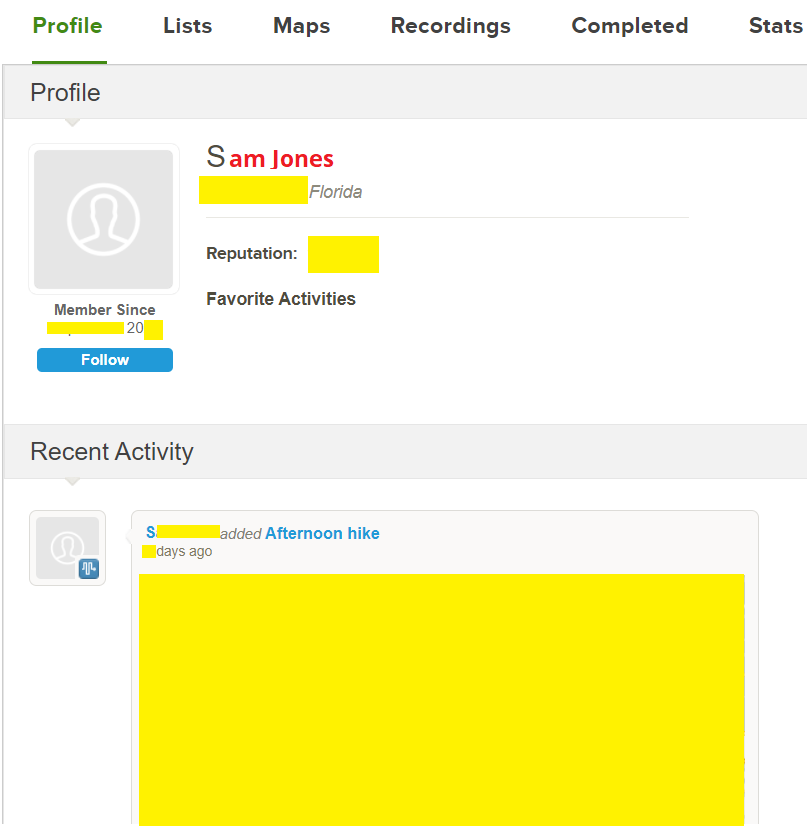
In the App on a phone, when you pull up to explore the area looking for trails you’re presented the pinpoints of a bunch of curated trails, as shown at left. You can click on a trail and get a description, trail map, reviews, popular activities and features. There is a slight problem in that reviews, I think, are public by default, but it appears that when your profile is private or individual recordings are private, your reviews aren’t shown.
In my search for trails, though, I’ve found lots of unlabeled trails. In other words, trails at parks, greenways and forests that haven’t been curated and cataloged. You can submit new trails for consideration, and I’ve done that with a few. I’ve also recorded via the app some hikes and walks that aren’t official trails, like when I dropped a rental truck off and walked home 5 miles because I needed to get a hike in that day or when my car was getting an oil change and I hiked to a park to kill time. Because of the challenge, I wanted to document these “hikes” to record my mileage. Now even though my recordings are private and my profile is private, uploading these recordings seemed even less problematic because they weren’t linked to an official trail and thus unfindable by the public. At least I assumed so. [Yes, privacy professionals, I know, AllTrails could be monetizing me by selling geolocation information to advertisers. I assume so, at least, with any app I use.]
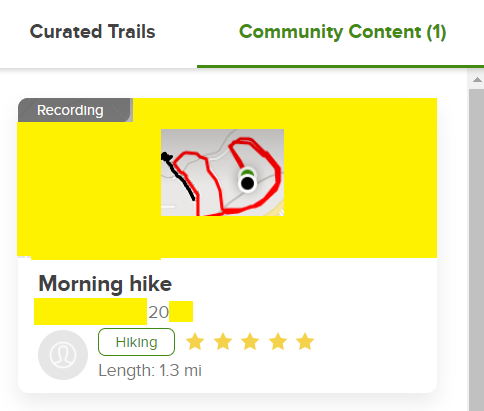
It turns out that my statement about recordings unlinked to trails is not quite accurate. In the App it appears to be true, but on the AllTrails website, you can look at curated trails OR community content.
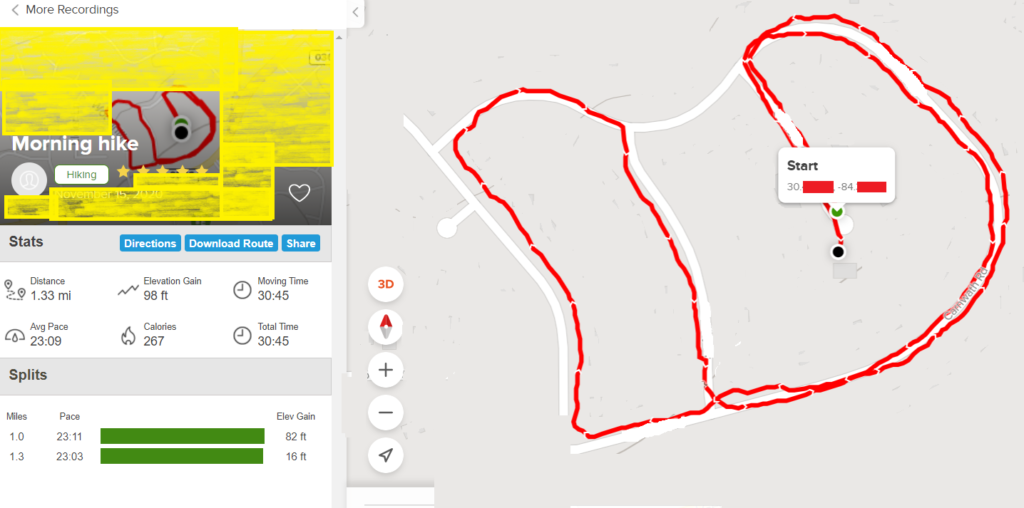
This community content contains all sorts of hikes people take, including official but uncurated trails, trips to visit grandmother in Ohio (I saw on where someone recorded their road trip) or walking around their neighborhood. I’ve yellowed out the map above to reduce the chance of someone finding this particular hiker’s location based on the road topography. Clicking on the recording in the list of community content leads to the details (shown below). As you can see this hiker left their house (black point) and walked around their neighborhood and turned off the recording as they approached their house at the end of the cul-de-sac (green point). Mousing over the endpoints yields the latitude and longitude to 5 decimal places, which is accurate to within a meter. I’ve attempted to obscure as much information as possible, like street names, exact lat/long and other houses, but I’m sure someone with enough resources could identify this from the unique street outline. However, I’m not going to make it easy.
You may be thinking, well this isn’t bad because I don’t know who lives at some random house (i.e. I don’t know their name, though it might be part of the public records on home ownership). It other words its an attribute disclosure about this person (their walk details) but not an identity disclosure. I won’t debate the problems of attribute disclosures in this blog but that’s not what’s happening here. Clicking the profile icon will take you to their profile. Note, this person did at least not upload a picture of themselves so the profile icon (under the words Morning Hike on the left) is generic. Unfortunately, they DID include their full name (changed to a gender neutral generic name below).
On my recent hiking challenge, I generally listen to podcasts, mostly privacy related. One I’ve become very fond of is Michael Bazzell’s “Privacy, Security and OSINT” podcast. It’s fairly frequent (I’m listening to podcasts daily now) and provides both tips on how to protect your privacy and OSINT (Open Source Intelligence) techniques, to which people need to be familiar with in order to protect their privacy.
Of course, being a privacy by design specialist, my take is people shouldn’t have to go to extremes to protect their privacy. The onus is on organizations to build better products and services. AllTrails, I like your app, really, I do. But it needs so many improvements from a privacy perspective. So many, in fact, I’d be happy to offer you some free consulting. Just contact me rjc at enterprivacy.com. I don’t mean to single AllTrails out. I’m sure this is a problem with many or most of the trail apps. AllTrails just happens to be the one I use.
For others who don’t want their organizations to be on the cover of the NY Times , sign up for some privacy by design training or contact me about a consulting engagement. Become a privacy hero with your customers.
Recently I had the pleasure of working with two start-ups in the AI space to help them consider privacy in their designs. Mr Young, a Canadian start-up, wants to use an intelligent agent to allow individuals to find resources available to them to improve their mental well-being. Eventus AI, a US based company, hopes to use AI to optimize the sales funnel from leads collected at events. Both recognized the potential privacy implications of their services and wanted to not only ensure compliance with legal obligations, but showcase privacy as an important aspect of their brand.
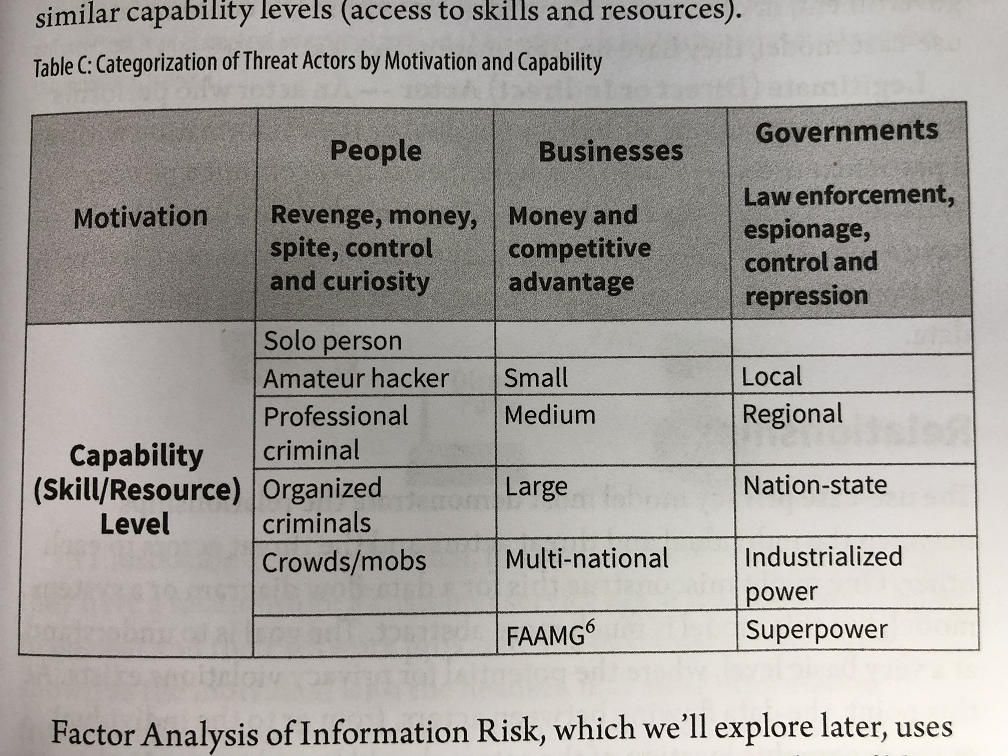
At the onset of my engagements, I had to think about how the intelligent agents driving them could threaten individuals’ privacy. In my previous work, threat actors were persons, organizations or governments, each with distinctive motives. People can be curious, seek revenge, trying to make money, or exert control. Organizations are generally driven by making money or creating competitive advantage. Governments invade privacy for law enforcement or espionage purposes. Less angelic governments may invade privacy out of desires for control or repression of their citizens.
Typically, when I think of software, it isn’t a “threat actor” in my privacy model. They don’t have independent motives. They are tools made by developers but they don’t have motives on their own. The question arises though; does AI represent a different beast? Does AI have “motives” independent of its creator? Clearly, we haven’t reached a stage where HAL 9000 refuses Dave’s command or Skynet determines humanity as a threat to its existence, but could something slightly less sentient manifest motive?
Still, I would argue that AI is not similar to other software. It can, in the sense, present a privacy threat beyond the intent of its creator. While not completely autonomous, AI does exhibit an ends justify the means approach to achieving its objective. The difference between AI and, say, a human employee, is the human can put their business objective in context of other social norms, whereas AI lacks this contextual understanding. I liken it to the dystopian analogy of robots being programmed to prevent humans from harming one another and determining the best way is to exterminate all humans. Problem solved! No more humans harming other humans. Like the genie granting a wish, they do exactly what they are told, sometimes with unintended and far-reaching consequences.
The motivation that I would ascribe to AI then is “programmatic goal-seeking.” It is not that AI seeks to invade privacy for independent purposes; rather it seeks whatever it’s been programmed to seek (such as ‘increasing engagements’). Privacy is the beautiful pasture bulldozed on AI’s straight-line path to its destination.
The question now becomes, from the perspective of a developer trying to build an AI into a system, how do you prevent privacy being a casualty of that relentless pursuit? I make no claims that my suggestion below in any way supplants all of the efforts to consider ethics in AI development (failed or successful), but rather this is the approach I take complements others. I think it gets us far along in a pragmatic and systematic way.
Before looking at tactics in the AI context (or anywhere really) there is a fundamental construct the reader must understand: the difference between data and information. Consider a photo of a person. The data is the photo – the bits, bytes, interpretations of how color should be rendered, etc. But a photo is rich with much information. It probably displays the gender of the individual, their hair color, their age, their ethnic background, perhaps their economic or social status. Even without geotagging, if the photograph has a distinctive background it could reveal the person’s location. Their subject’s hairstyle and dress and the quality and makeup of the photo might suggest the decade it was recorded. Giving over that photo to someone not only gives them the bits and the bytes but also gives them all of that rich information.
In general, for privacy by design, I use Jaap-Henk Hoepman’s strategies and tactics to reduce privacy risks. Just as they can be applied to other threat actors, I think they are equally applicable here. Returning to how to use Hoepman’s strategies against AI, consider the following example:
Your company has been tasked with designing an AI based solution to sort through thousands of applicants to find the one best suited for a job. You’re concerned the solution might adversely discriminate against candidates from ethnic minority populations. If you’re questioning whether this is even a “privacy” issue, I’d point you to the concept of Exclusion under the Solove Taxonomy. We’re (well the AI) is potentially using information, ethnicity, without knowledge and participation of the individuals, an Exclusion violation.
How then can we seek to prevent this potential privacy violation?
Two immediate tactics come to mind. These are by no means the only tactics that could or should be employed but illustrative. The first is stripping which falls under the Minimize strategy and my ARCHITECT supra-strategy. Stripping refers to removing unnecessary attributes. Here, the attribute we need to remove is ethnicity. This isn’t as simple as removing ethnicity as a data point given to the AI. Rather, returning to the distinction between data and information, we need to examine any instance where ethnicity could be inferred from data, such as a name or cultural distinctions in the way candidates my respond to certain questions. This also includes ensuring that training data doesn’t contain hidden biases in its collection.
The second tactic is auditing which falls under the Demonstrate strategy and my SUPERVISE supra-strategy. AI already employs validation data to ensure that the AI is properly goal seeking (i.e. achieving its primary purpose). Review of this validation process should be used to also continue ensuring that the AI isn’t inferring ethnicity somehow (that we failed to strip out) and using that information inappropriately as part of its goal seeking objective. If it turns out it is, then, similar to a human employee, the AI might need retraining with new, further sanitized, data.
While AI represents a new and potentially scary future, with proper design considerations and strategic systematic approaches, we reduce the potential privacy risks they would otherwise create.
In the early years of the aught decade, Dan Solove, then assistant professor of law at Seton Hall Law School presaged that the new paradigm for privacy in the Internet age wasn’t George Orwell’s 1984 but rather Franz Kafka’s The Trial. In the book, the protagonist is subject to a secret trial in which he knows not the charges against him or the evidence used. He is not allowed to participate in the proceedings or dispute the evidence. In the end, the character is executed having never learned what the charges were. A few years later when Professor Solove developed his taxonomy of privacy, which categorized cognizable privacy violations, this form of privacy violation became known as Exclusion: the use of information about an individual without the individual’s knowledge or ability to participate. Solove’s taxonomy encompasses 17 distinct privacy violations spanning four broad categories: information collection, information processing, information dissemination and the non-information privacy issues in invasion. Exclusion is a particularly pernicious violation because it combines two fundamental forces that underlie many issues around privacy, namely imbalance in information and imbalance in power between the organization and the individual. In The Trial, the government is the perpetrator of this type of violation. Historically, government actors is where one mostly find this because government’s power monopoly prevents individual choice and the impact, such as loss of liberty, can be devastating. The unfairness of exclusion was crucial in criticisms of the US government’s no-fly list, which contained names of individuals who didn’t know they were on the list, even once known were unable to know or dispute the information used against them. Concern over exclusion also underpins the original formation of the Fair Information Practices (which was primarily aimed at government databases in the 1970s) to prevent secret databases to which individual couldn’t dispute inaccuracies. In the commercial realm, these concepts first took hold in credit reporting industry and the Fair Credit Reporting Act’s requirement for transparency and a dispute mechanism.
I’m a heavy user of Professor Solove’s taxonomy in my privacy by design training because it help participants categorize different types of privacy violations. It highlights, for most participants, that insecurity of data (which seems to be almost a fetishistic focus for many) is really only the tip of the privacy iceberg. I like to joke in my training that I’ve had every single privacy violation foisted on me in some fashion or another. Using anecdotes helps my students relate to the violations in a way that defining and explaining doesn’t. Personal stories convey even more than sensational news stories can. In one instance, I talk about how a cashier at fast food restaurant identified my then girlfriend to send her a Facebook friend request. I show students an Asian dating website where my picture was appropriated in advertising. Exclusion really hits home when I ask students if they’ve ever been put on hold and told their call will be answered by the next available operator. I discuss how some companies use secret profiles of their “problem” customers to constantly kick them to the back of the queue without the customer being able to know or dispute this status.
My most recent example comes from Amazon and is detailed below.
Last month I was traveling in Europe to attend a few privacy related events and conduct some training for Deloitte Romania. In Bucharest, I taught a CIPT course as well as my Privacy by Design class, relabeled Data Protection by Design for the EU audience. While in Romania I attempted to place an order on Amazon for an electronic gift card. Apparently this raised red flags within Amazon’s systems (an electronic gift card ordered by an American consumer but from Romania, which they probably inferred from my IP address). The order was canceled. Amazon also blocked access to my account for 5 hours.
After 5 hours, I followed the instructions, which included resetting my password. I was back in and figuring it was safe since I re-authenticated my access to my email, re-placed my order . Of course, it wasn’t. Amazon repeated it’s effort but this time required that I call to reinstate my account.
I called Amazon, spoke with a customer service agent and after answering quite a few questions (like how long I had had my Amazon account, whether I had any linked devices, etc.), my account access was reinstated and I was able to reset my password and log in. I decided NOT to try and replace my order until I returned to the US the follow week, which I did. At this point my order went through and I thought everything was behind me. I even subsequently ordered Woody Hartzog’s new book Privacy’s Blueprint, without issue. [Side note, excellent book, highly recommended, just don’t order it from Amazon ;-)]
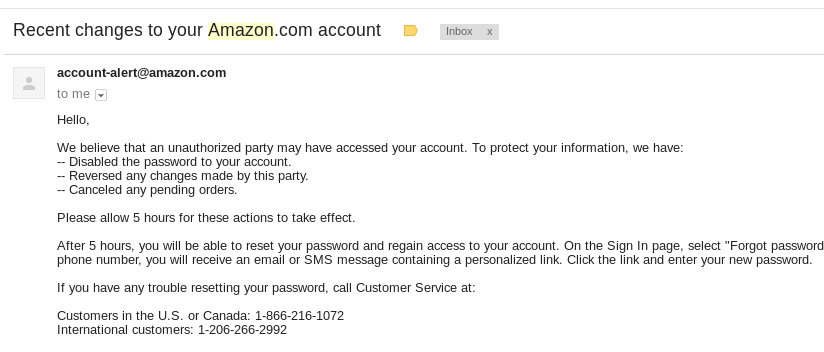
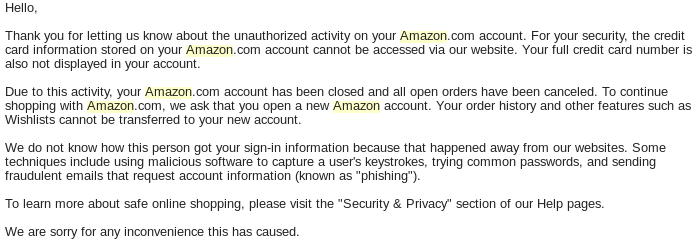
About two weeks later I’m in D.C. attending the Privacy Law Scholar’s Conference and ordered a present for a friend off their wish-list. BAM! My account was again shutdown. I didn’t realize it, since I was off doing actual work, but when I tried to check the status of the order I realized that they had shut my account down again. I called customer service but the best they could offer was to submit an email to the “Account Specialist” team. At 1:30 AM later than morning I received the following email:
Thank you for letting us know about the unauthorized activity on your Amazon.com account. For your security, the credit card information stored on your Amazon.com account cannot be accessed via our website. Your full credit card number is also not displayed in your account.
Due to this activity, your Amazon.com account has been closed and all open orders have been canceled. To continue shopping with Amazon.com, we ask that you open a new Amazon account. Your order history and other features such as Wishlists cannot be transferred to your new account.
Are you really sorry for the inconvenience this has caused, Amazon?
Note the email starts out “Thank you for letting us know about unauthorized activity.” I quickly responded that there was no authorized activity (and I certainly didn’t let them know). Oddly enough there was another email at 9:30AM that morning (AFTER the account closure) suggesting I needed to call to reset my password again. I did call but the customer service agent was only able to offer to send another email to the Account Specialist team.
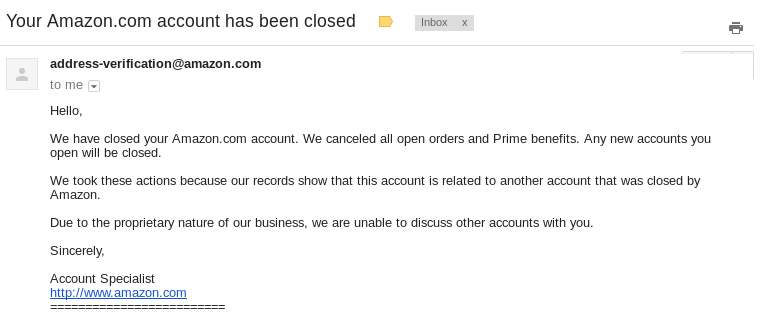
Frustrated at this point, and not wanting my friend’s present further delayed, I dutifully followed the instructions about using another Amazon account, after all Amazon specifically told me that “To continue shopping with Amazon.com, we ask that you open a new Amazon account.” I went into my business account which I had previously used to host AWS instances for various business projects.However, my attempt to complete my order was similarly thwarted. I initially received an email to confirm my billing address, which I quickly replied. I was then presented with this sternly worded email:
“Any new accounts you open will be closed.”
So, despite having told me previously to open a new account to continue shopping, Amazon has decided they will close any account I open in the future, with no discussion of why this was occurring, no information as to what led to this decision and no opportunity to dispute or appeal it. Some faceless, nameless, bureaucratic Account Specialist had declared me persona non-grata. Assuming the Account Specialist is even a person and not a bot.
My virtual death as an Amazon customer.
Quite a few of the most recent complaints on BBB for Amazon are about inexplicable account closures. Luckily, my dependence on Amazon is negligible. Though I’ve been a customer 10 years, I wasn’t using AWS actively and canceled Prime just a few months ago because it wasn’t worth the costs. However, I could only imagine how this could have affected me. Having dinner the next day with a friend in the privacy/security industry he was shocked and concerned because he orders virtually everything off Amazon as I know many do. What if I used Kindle, would I lose all my purchases? I’d be more concerned about those who’s livelihood depended on the Amazon service. What if I was an associate and depended on Amazon referrals for this blog’s revenue? Or a reseller on Amazon? What I had had extensive use of AWS for my business? Perhaps if I was in one of these categories they would have been more circumspect in their closing my account. Perhaps I would have had another avenue to escalate, but as a regular consumer I certainly didn’t.
As for my particular circumstances, first and foremost, I’m a bit miffed that I can’t get my order history and wish-lists. I have frequently referred to my order history when doing my year end taxes as some of my purchases are business related. Also, I’ve spent years adding things to my wish-list, mostly books that I’ll probably never get around to ordering, though I have had relatives order them occasionally for birthdays in the past. There is no way for me to reconstruct this information. Account closure seems particular vindictive. Of course, I don’t know why they closed my account, so it’s hard to say. I can only guess that they suspected some sort of fraudulent activity despite all the charges to my account having always gone through and never disputed. If potential fraud is the reason, they could have suspended ordering privileges, but allowed the account to still access historical data. One problem with behemoths such as Amazon is that by providing multiple services to which people may become dependent, a problem in one area can have an out-sized impact on the individual. Segmentation of services is important in reducing risks. A problem with my personal account shouldn’t affect my business account. A problem with ordering physical products shouldn’t affect my Prime video membership or Kindle e-books. A problem with my use of the affiliate program shouldn’t affect my personal use as a shopper. Etc.
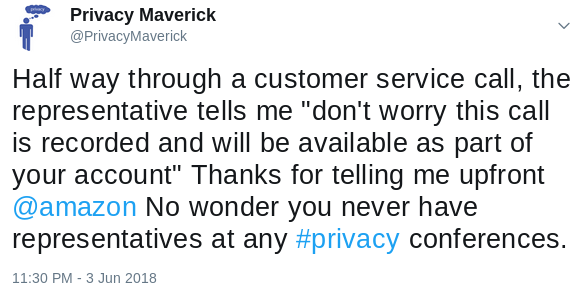
Maybe my tweet complaining that they were recording my call without informing me up front was the reason they closed my account.
Were I in the EU, I might have some additional recourse under the newly passed GDPR. Namely
Under Article 15 I could receive the personal information they have on me, including not only my wish-list and order history, but potentially whatever information was the basis for the account closure.
Under Article 16, I could potentially rectify any inaccurate data about me which may have lead to the decision to close my account.
Under Article 20, the right to data portability. While this probably doesn’t apply to my order history, since it’s arguable whether I “supplied” the information, it would apply to my wish-list, since that subjective preference data is something I supplied when I clicked “Add to my wish-list”
Under Article 21, the right not to be subject to automated decision making. More specifically: the data controller shall implement suitable measures to safeguard the data subject’s rights and freedoms and legitimate interests, at least the right to obtain human intervention on the part of the controller, to express his or her point of view and to contest the decision.
Of course, I don’t know if the account deletion determination was based on an automated decision, but I suspect in part, they have some AI making a determination at some point to suspend or restrict use of my account.
Once it’s available, I’ve been considering applying for Estonia’s digital nomad visa. If I still care at that point, when I’m in the EU, I might subject Amazon to some of these rights to which I’m not afforded as someone in the US. It’s highly likely I won’t care at that point. As I stated, my use of Amazon, unlike many associates of mine, has been limited. Maybe my account closure is a good thing as it pushes me closer to removing my reliance on the big tech firms. I’ve closed my Facebook account and haven’t used Facebook in almost 6 months (though to be transparent, I still use Instagram). I moved several years ago to a Libre 15 by Purism running PureOS (an Ubuntu Linux variant) and away from Windows, though again in full transparency, I purchased a Microsoft Surface Pro for presentations (on newegg, btw, where I’ll obviously be shopping more from now on). At least Microsoft is more in the pro-privacy camp. I’m still trying to extricate myself from Google. I purchased an iPhone (again on newegg) for the first time having been an Android user for many years. I’m still, unfortunately, on GoogleFi because I like that it works when I travel internationally. I still use Gmail for my personal email, though not for business anymore, having my own domain. One reason I still use Gmail is when I have to give my email address to someone orally, I know they aren’t going to misspell gmail.com like they might privacymaverick.com.
I’ve fashioned myself a Privacy and Trust Engineer/Consultant for over a year now and I’ve focused on the Trust side of Privacy for a few years, with my consultancy really focused on brand trust development rather than privacy compliance. Illana Westerman‘s talk about Trust back at the 2011 Navigate conference is what really opened my eyes to the concept. Clearly trust in relationships requires more than just privacy. It is a necessary condition but not necessarily sufficient. Privacy is a building block to a trusted relationship, be it inter-personal, commercial or between government and citizen.
More recently, Woody Hartzog and Neil Richard’s “Taking Trust Seriously in Privacy Law” has fortified my resolve to pushing trust as a core reason to respect individual privacy. To that end, I though about refactoring the 7 Foundational Principles of Privacy by Design in terms of trust, which I present here.
Proactive not reactive; Preventative not remedial → Build trust, not rebuild Many companies take a reactive approach to privacy, preferring to bury their head in the sand until an “incident” occurs and then trying to mitigate the effects of that incident. Being proactive and preventative means you actually make an effort before anything occurs. Relationships are built on trust. If that trust is violated, it is much harder (and more expensive) to regain. As the adage goes “once bitten, twice shy.”
Privacy as the default setting → Provide opportunities for trust Users shouldn’t have to work to protect their privacy. Building a trusted relationship occurs one step at a time. When the other party has to work to ensure you don’t cross the line and breach their trust that doesn’t build the relationship but rather stalls it from growing.
Privacy embedded into the design → Strengthen trust relationship through design Being proactive (#1) means addressing privacy issues up front. Embedding privacy considerations into product/service design is imperative to being proactive. The way an individual interfaces with your company will affect the trust they place in the company. The design should engender trust.
Full functionality – positive sum, not zero sum → Beneficial exchanges Privacy, in the past, has been described as a feature killer preventing the ability to fully realize technology’s potential. Full functionality suggest this is not the case and you can achieve your aims while respecting individual privacy. Viewed through the lens of trust, commercial relationships should constitute beneficial exchanges, with each party benefiting from the engagement. What often happens is that because of asymmetric information (the company knows more than the individual) and various cognitive biases (such as hyperbolic discounting), individuals do not realize what they are conceding in the exchange. Beneficial exchanges mean that, despite one party’s knowledge or beliefs, they exchange should still be beneficial for all involved.
End to end security – full life-cycle protection → Stewardship This principle was informed by the notion that sometimes organizations were protecting one area (such as collection of information over SSL/TLS) but were deficient in protecting information in others (such as storage or proper disposal). Stewardship is the idea that you’ve been entrusted, by virtue of the relationship, with data and you should, as a matter of ethical responsibility, protect that data at all times.
Visibility and transparency – keep it open → Honesty and candor Consent is a bedrock principle of privacy and in order for consent to have meaning, it must be informed; the individual must be aware of what they are consenting to. Visibility and transparency about information practices are key to informed consent. Building a trusted relationship is about being honest and candid. Without these qualities, fear, suspicion and doubt are more prevalent than trust.
Respect for user privacy – keep it user-centric → Partner not exploiter Ultimately, if an organization doesn’t respect the individual, trying to achieve privacy by design is fraught with problems. The individual must be at the forefront. In a relationship built on trust, the parties must feel they are partners, both benefiting from the relationship. If one party is exploitative, because of deceit or because the relationship is achieved through force, then trust is not achievable.
I welcome comments and constructive criticisms of my analysis. I’ll be putting on another Privacy by Design workshop in Seattle in May and, of course, am available for consulting engagement to help companies build trusted relationships with consumers.
This post is not an original thought (do we truly even have “original thoughts”, or are they all built upon the thoughts of others? I leave that for others to blog about). I recently read a decade old paper on price discrimination and privacy from Andrew Odlyzko. It was a great read and it got more thinking about many of the motivations for privacy invasions, particularly this one.
Let me start out with a basic primer on price discrimination. The term refers to pricing items based on the valuation of the purchaser, in other words discrimination in the pricing of goods and services between individuals. Sounds a little sinister, doesn’t it? Perhaps downright wrong, unethical. Charging one price for one person and a different price for another. But price discrimination can be a fundamental necessity in many economic situations.
Here’s an example. Let’s say I am bringing cookies to a bake sale. For simplicity, let’s say there are three consumers at this sale (A, B and C). Consumer A just ate lunch so isn’t very interest in a cookie but is willing to buy one for $0.75. Consumer B likes my cookies and is willing to pay $1.00. Consumer C hasn’t eaten and loves my cookies but only has $1.50 on him at the time. Now, excluding my time, the ingredients for the cookies cost $3.00. At almost every price point, I end up losing money
Sale price $0.75 -> total is 3x$0.75 = $2.25
Sale price $1.00 -> total is 2x$1.00 = $2.00 (Consumer A is priced out as the cost is more than they are willing to pay)
Sale price $1.50 -> total is 1x$1.50 = $1.50 (Here both A and B are priced out)
However, if I was able to charge each Consumer their respective valuation of my cookies, things change.
$0.75+$1.00+$1.50= $3.25
Now, not only does everyone get a cookie for what they were willing to pay, I cover my cost and earn some money to cover my labor in baking the cookie. Everybody is happier as a result, something that could not have occurred had I not been able to price discriminate.
What does this have to do with Privacy? The more I know about my consumers, the more I’m able to discover their price point and price sensitivity. If I know that A just ate, or that C only has $1.50 in his pocket, or that B likes my cookies, I can hone in on what to charge them.
Price discrimination it turns out is everywhere and so are mechanisms to discover personal valuation. Think of discounts to movies for students, seniors and military personnel. While some movie chain may mistakenly believe they are doing it out of being a good member of society, there real reason is they are price discriminating. All of those groups tend to have less disposable income and thus are more sensitive to where they spend that money. Movies theaters rarely fill up and an extra sale is a marginal income boost to the theater. This is typically where you find price discrimination, where the fix costs are high (running the theater) but the marginal cost per unit sold are low. Where there is limited supply and higher demand, the seller will sell to those willing to pay the highest price.
But what do the movie patrons have to do to obtain these cheaper tickets? They have to reveal something about themselves….their age, their education status or their profession in the military.
Other forms of uncovering consumer value also have privacy implications. Most of them are very crude groupings of consumer in to bucket, just because our tools are crude, but some can be very invasive. Take the FAFSA, the Free Application for Federal Student Aid. This form is not only needed for U.S. Federal loans and grants, but many universities rely on this form to determine scholarships and discounts. This extremely probing look into someones finances is used to perform price discrimination on students (and their parents), allowing those with lower income and thus higher price sensitivity to pay less for the same education as another student from a wealthier family.
Not all methods of price discrimination affect privacy, for instance, bundling. Many consumers bemoan bundling done by cable companies who don’t offer an ala carte selection of channels. The reason for this is price discrimination. If they offered each channel at $1 per month, they would forgo revenue from those willing to pay $50 a month for the golf channel or those willing to pay $50 a month for the Game Show Network. By bundling a large selection of channel, many of whom most consumers don’t want, they are able to maximize revenue from those with high price points for certain channels as well as those with low price points for many channels.
I don’t have any magic solution (at this point). However, I hope by exposing this issue more broadly we can begin to look for patterns of performing price discrimination without privacy invasions. One of the things that has had me thinking about this subject is a new App I’ve been working on for privacy preserving tickets and tokens for my start-up Microdesic. Ticket sellers have a problem price discriminating and tickets often end up on the secondary market as a result.
[I’ll take the bottom of this post to remind readers of two upcoming Privacy by Design workshops I’ll be conducting. The first is in April in Washington, D.C. immediately preceding the IAPP Global Summit. The second is in May in Seattle. Note, the tickets ARE price discriminated, so if you’re a price sensitive consumer, be sure to get the early bird tickets. ]