Recently I had the pleasure of working with two start-ups in the AI space to help them consider privacy in their designs. Mr Young, a Canadian start-up, wants to use an intelligent agent to allow individuals to find resources available to them to improve their mental well-being. Eventus AI, a US based company, hopes to use AI to optimize the sales funnel from leads collected at events. Both recognized the potential privacy implications of their services and wanted to not only ensure compliance with legal obligations, but showcase privacy as an important aspect of their brand.
At the onset of my engagements, I had to think about how the intelligent agents driving them could threaten individuals’ privacy. In my previous work, threat actors were persons, organizations or governments, each with distinctive motives. People can be curious, seek revenge, trying to make money, or exert control. Organizations are generally driven by making money or creating competitive advantage. Governments invade privacy for law enforcement or espionage purposes. Less angelic governments may invade privacy out of desires for control or repression of their citizens.
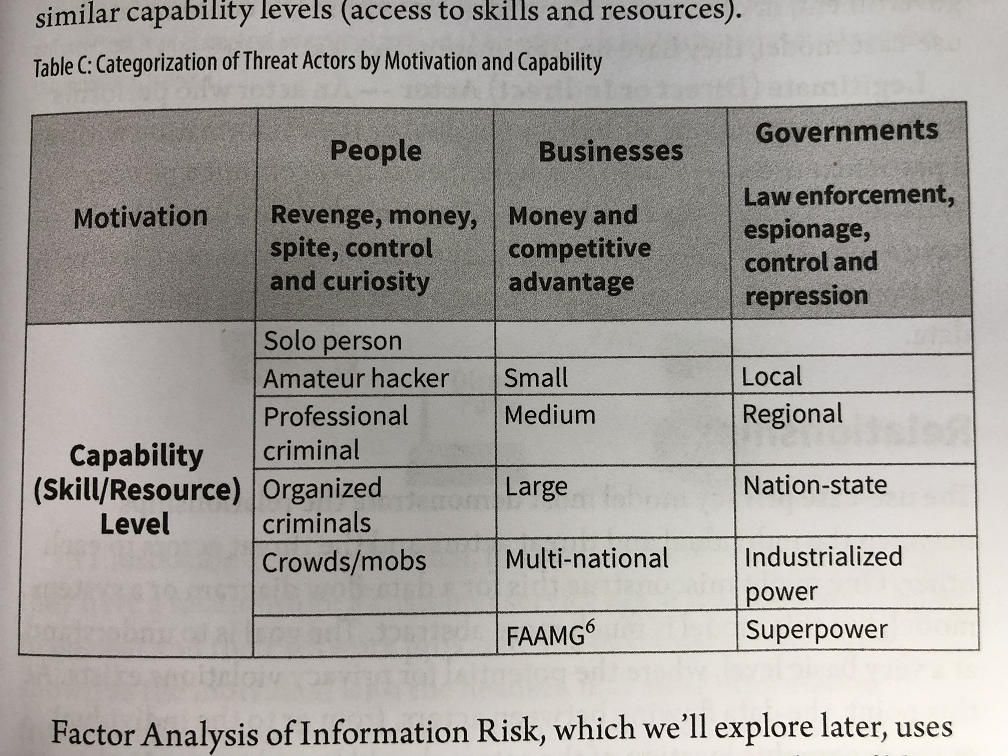 Figure 1 From the book Strategic Privacy by Design chapter on Actors
Figure 1 From the book Strategic Privacy by Design chapter on Actors
Typically, when I think of software, it isn’t a “threat actor” in my privacy model. They don’t have independent motives. They are tools made by developers but they don’t have motives on their own. The question arises though; does AI represent a different beast? Does AI have “motives” independent of its creator? Clearly, we haven’t reached a stage where HAL 9000 refuses Dave’s command or Skynet determines humanity as a threat to its existence, but could something slightly less sentient manifest motive?
Still, I would argue that AI is not similar to other software. It can, in the sense, present a privacy threat beyond the intent of its creator. While not completely autonomous, AI does exhibit an ends justify the means approach to achieving its objective. The difference between AI and, say, a human employee, is the human can put their business objective in context of other social norms, whereas AI lacks this contextual understanding. I liken it to the dystopian analogy of robots being programmed to prevent humans from harming one another and determining the best way is to exterminate all humans. Problem solved! No more humans harming other humans. Like the genie granting a wish, they do exactly what they are told, sometimes with unintended and far-reaching consequences.
The motivation that I would ascribe to AI then is “programmatic goal-seeking.” It is not that AI seeks to invade privacy for independent purposes; rather it seeks whatever it’s been programmed to seek (such as ‘increasing engagements’). Privacy is the beautiful pasture bulldozed on AI’s straight-line path to its destination.
The question now becomes, from the perspective of a developer trying to build an AI into a system, how do you prevent privacy being a casualty of that relentless pursuit? I make no claims that my suggestion below in any way supplants all of the efforts to consider ethics in AI development (failed or successful), but rather this is the approach I take complements others. I think it gets us far along in a pragmatic and systematic way.
Before looking at tactics in the AI context (or anywhere really) there is a fundamental construct the reader must understand: the difference between data and information. Consider a photo of a person. The data is the photo – the bits, bytes, interpretations of how color should be rendered, etc. But a photo is rich with much information. It probably displays the gender of the individual, their hair color, their age, their ethnic background, perhaps their economic or social status. Even without geotagging, if the photograph has a distinctive background it could reveal the person’s location. Their subject’s hairstyle and dress and the quality and makeup of the photo might suggest the decade it was recorded. Giving over that photo to someone not only gives them the bits and the bytes but also gives them all of that rich information.
In general, for privacy by design, I use Jaap-Henk Hoepman’s strategies and tactics to reduce privacy risks. Just as they can be applied to other threat actors, I think they are equally applicable here. Returning to how to use Hoepman’s strategies against AI, consider the following example:
Your company has been tasked with designing an AI based solution to sort through thousands of applicants to find the one best suited for a job. You’re concerned the solution might adversely discriminate against candidates from ethnic minority populations. If you’re questioning whether this is even a “privacy” issue, I’d point you to the concept of Exclusion under the Solove Taxonomy. We’re (well the AI) is potentially using information, ethnicity, without knowledge and participation of the individuals, an Exclusion violation.
How then can we seek to prevent this potential privacy violation?
Two immediate tactics come to mind. These are by no means the only tactics that could or should be employed but illustrative. The first is stripping which falls under the Minimize strategy and my ARCHITECT supra-strategy. Stripping refers to removing unnecessary attributes. Here, the attribute we need to remove is ethnicity. This isn’t as simple as removing ethnicity as a data point given to the AI. Rather, returning to the distinction between data and information, we need to examine any instance where ethnicity could be inferred from data, such as a name or cultural distinctions in the way candidates my respond to certain questions. This also includes ensuring that training data doesn’t contain hidden biases in its collection.
The second tactic is auditing which falls under the Demonstrate strategy and my SUPERVISE supra-strategy. AI already employs validation data to ensure that the AI is properly goal seeking (i.e. achieving its primary purpose). Review of this validation process should be used to also continue ensuring that the AI isn’t inferring ethnicity somehow (that we failed to strip out) and using that information inappropriately as part of its goal seeking objective. If it turns out it is, then, similar to a human employee, the AI might need retraining with new, further sanitized, data.
While AI represents a new and potentially scary future, with proper design considerations and strategic systematic approaches, we reduce the potential privacy risks they would otherwise create.