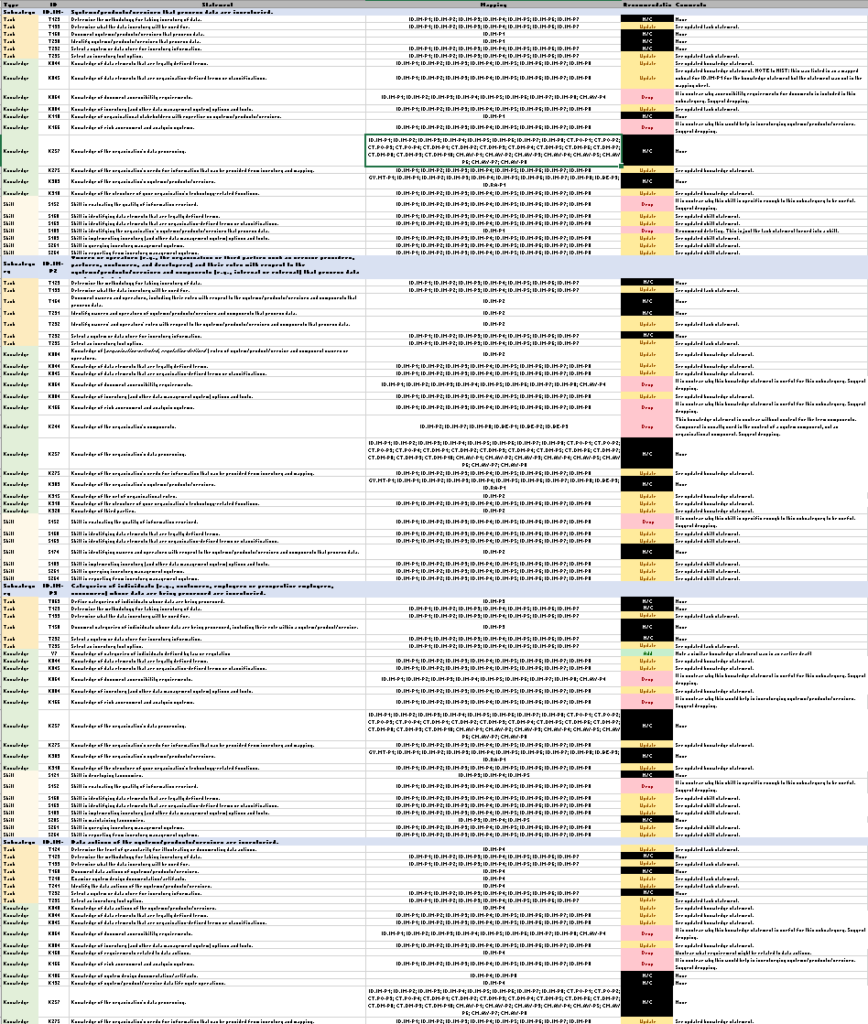
Back in 2021, NIST launched it Privacy Workforce Working Group to identify the tasks, knowledge and skills of privacy workforce of tomorrow. I was happy to be part of this effort. Late last year, after three years of effort, NIST published its initial public draft. They provided only 45 days to comment. I had assembled a team prior to that to provide commentary to NIST on this draft, and, in fact, we had been working for months on previously released (non-public) draft. Our team reviewed nearly 2000 statements linked to 13 subcategories of outcomes. We made comments, suggested remapping some statements, provided suggested rewrites and alternatives, justifications for deleting comments
We suggested Tasks: 44 deletions, 151 updates and no changes to 131 statements Knowledge: 63 deletions, 103 updates and no changes to 171 statements Skill: 83 deletions, 90 updates and no changes to 121 statements
Beyond that, we had dozens of recommendations to add/remove/replace statements associated with subcategories, as well as dozens of readd from previous private drafts that were dropped from the public release. What follows is our suggested edits and introductory letter.
Thanks to Anza Abbas (Enterprivacy Consulting Group) Andrew Berry (Enterprivacy Consulting Group) Nandita Narla (Institute of Operational Privacy Design) Vandana Padmanabhan (Independent)
I recently had the distinct pleasure of reading Robert Sapolsky’s book Determined: A Science of Life Without Free Will. Throughout my reading I kept pondering in the back of my mind the implications for the privacy profession and the general field of privacy. This blog post is an outgrowth of those thoughts.
If you can’t tell from the title, the book provides a thorough debunking of the notion that we, as humans, have free will. Primarily written from a biological perspective, the book delves (note, this was not written by AI) into other subject areas and, in fact, the author says that a singular discipline approach to discussing free will can neither dismiss nor promote it. As with many concepts, a multi-disciplinary approach is needed. The book does an excellent job of breaking down the biology of why our actions are predetermined. Our “decisions” are predicated on the neurochemical reactions that happened in our brain immediately preceding it, which was determined by the chemicals in you at the time and neurons that have been strengthened and weakened over your lifetime, which were done so by the culture that has been built up in the decades and centuries preceding your life and in to which you were born and grew, which were orchestrated by the quirks of developments of social structure by our evolutionary path as social creatures, which was guided by the struggle to survive by genes and their interactions with their natural environment. It’s turtles all the way down.
Sapolsky makes some excellent arguments both biological and historical. On the biological side, take the sea slug (Aplysia californica) which studies have demonstrated, despite not having a brain, can learn behavior to avoid an electric shock. In demonstrating the “decision” to choose a path which avoids electric shock, researchers have shown the way sensory neurons and motor neurons change, through the use of inhibitor nodes and excitatory nodes (basically neurotransmitter bonding). This creates a complex decision system in simplistic neuron cells that cause the sea slug to “decide” when to withdraw or not withdraw its gills. The same neurochemical reinforcement that causes the sea slug to exhibit this behavior, causes humans to make “decisions” based on prior stimuli and reinforcements. You didn’t decide to push that button, everything that preceded the button pushing led you to push it. On the historical side, Sapolsky demonstrates that as we’ve been learning more and more about how the brain works, we’ve been traveling down a road towards the inevitable conclusion of a lack of free will. For centuries, seizures were deemed an example of demonic possession, caused by moral turpitude or invitation of such possession. Thankfully, we now know seizures are caused by misfiring neurons, themselves the result of stimuli, brain development, genetics and a host of other factors independent of the afflicted. Beyond making reasoned arguments against free will, Sapolsky debunks many of the arguments for free will. One such claim that quantum uncertainty creates free will seems particularly easy to knock down. Even if you get past the fact that the quantum doesn’t affect the macroscale of neurons in any meaningful way, such a result would only create random decisions not free will, as people understand the concept. One further note, Sapolsky doesn’t argue that being deterministic biological creatures makes us predictable, rather the complexity of the inputs, in fact, makes us unpredictable (think Butterfly Effect).
Beyond arguing for a lack of free will, where is Sapolsky going with this? Just as we don’t punish epileptics for inviting demons into themselves, civilized society is coming more to understand that the root causes of antisocial behavior are not people “deciding” to do ill but because of their upbringing, their childhood, their exposure to cultural forces, their genes, the chemical they’ve been exposed to, their lack of nutrition in utero which contributed to irregular development of the prefrontal cortex, evolutionary forces which causes people to defect from social goods to better themselves and causes social animals, like humans, to punish defectors to benefit the greater good. Sapolsky goes on to argue that, rather than punish antisocial behavior, which our brains have been evolutionarily shaped to do, a more appropriate and just way of approaching this would be to both recognize that it’s not a decision to be morally corrupt and the best way for society to deal with antisocial behavior is not to punish but alter those factors which lead to antisocial behavior (think early nutrition), deter and take away the ability for those with antisocial inclinations to act (incarcerate not to punish but to protect society). Whether or not my measly three paragraphs convinces you we have no free will, I would highly encourage you to read the book Determined. For those of you whose brain is predetermined not to read a 400+ page book, Sapolsky has done numerous interviews, including the one with Neil deGrasse Tyson that led me to his book. Please take the time and pass it on.
Now, what the heck does this have to do with privacy, you may be wondering. In reading the book, I was struck by three thoughts. First, if we have no free will, where does this leave consent? You didn’t decide to consent. All of the influences, conditions, and history, basically everything that you had no control over, led up to the moment of you either granting or denying authorization. What can it mean for consent to be freely given if you have no free will? First off, I’d argue that, just like the sea slug, our decisions need not be based on free will. Those decisions are based on precedent (through culture, evolution, or even personal history) which has built up in our brain’s neurons to protect us. This is why kids are risk taking and adults tend to be risk averse and why children need, potentially, more protection (because we’ve learned and they haven’t). So, just because our decision is based on the strengthening of neurochemical transmitters built up over time and not “free will” doesn’t mean that our decisions are no less individualistic, owing to our personal circumstances, and thus deserving of individual respect.
However, this brings me to my second thought. Given that we know that our decisions are based on this neurochemical build up, the manipulation of this seems even more problematic. It further suggests others, acting in their interest, can tweak and hone in their methods to train our brains to make the decisions that are best for them and not ourselves. I’ve long noted the problem of the normalization of privacy invasions changing social norms on what is considered a privacy invasion. Like when Facebook introduced the newsfeed which is now the de facto operation of social media sites, or when the normalization of facial recognition for authentication to one’s phone spills over to hardly a soul disputing the use of facial recognition at airports and borders. The point is we can, and will, be manipulated, and our autonomy degraded. This has ramifications for deceptive designs, not just those that deceive and lead us to decisions in contravention to how our brain would respond with all the stimuli, but those that reprogram the brain to make different decisions. AI has the frightening possibility that it won’t just deceive, but in a maximization effort to drive results, will find pathways that actually change our brain’s makeup.
My third and final thought on privacy and free will has more to do with our understanding of privacy and how this is directed by cultural and evolutionary development over centuries and millennia. Most privacy professionals have long recognized a cultural difference to perceptions of privacy and privacy invasive acts. It turns out many cultural differences are actually exhibited in brain makeup, mostly in the prefrontal cortex. Similarly, brain composition, as determined by your upbringing, determines your moral compass. Certain groups value obedience, loyalty and purity, while others favor fairness and harm avoidance. The former tend to be deontologists, the latter consequentialists. Given privacy’s placement as a social norm, people’s perception of privacy will necessarily be driven by everything that has come before. Ultimately, the question is how I can utilize that to drive the discussion forward.
This week, I voraciously consumed a 2023 law review article published by María Angel and Ryan Calo criticizing Daniel Solove’s Taxonomy of Privacy and Professor Solove’s 2024 critique of that paper and other criticisms. Solove’s Taxonomy has been highly influential and plays an enormous role in my work, from it uses in my book Strategic Privacy by Design, to its help in formulating privacy values underpinning my use of the NIST Privacy Framework, and finally as a model of normative consequences in privacy threat and risk modeling. Solove’s Taxonomy has been foundational in my work as a privacy engineer. I recall one of my interns once saying “but doesn’t every privacy professional know Solove’s Taxonomy?” to which I, disheartened, replied “No.” What follows is my, rather utilitarian, defense of the taxonomy.
As Solove describes in his response, Angel & Calo (2023) seek a sort of privacy essentialism, a way of framing and talking about privacy that creates clear boundaries between it and other fields. However, the concept of privacy mirrors the boundaries of privacy harms — fuzzy, mutable and with not only disagreement but differences owing to culture and subjectivity. I’ve always viewed privacy conceptually as a bubble separating the individual from society: the interior the province of the individual and the exterior the province of society. Historically, the bubble was your physical private space, separating you from the public space: your house, your thoughts, things with clear demarcation lines between inside (your house, yard or head). The modern bubble, though, metaphysically represents you, your tendrils into society, everything there is about your existence. Whether it be your physical presence, your information, your acquaintances, or your property, the bubble is, metaphorically, you. Some of us have small bubbles, some large. That bubble can be breached, but the bubble is also hazy. The boundary is a tug of war between individuals and society, “an actual [subjective] expectation of privacy … that society is prepared to recognize as ‘reasonable’” (Katz v. United States). Privacy is the study or attempt to define this boundary between you and not you, who is allowed in and who is not.
As the volleys between Solove and his detractors suggest, these boundary setting problems implicate many other social issues. This is where he and Angel & Calo (2023) diverge. They view privacy essentialism, as Solove terms it, as clear knowledge of the boundary line between privacy and not privacy. In other words, which boundary line we’re talking about should not be subject to debate. Rather, the debate, the province of the study of privacy, is where to draw the line. Note the conceptual difference between the line between privacy and not privacy versus, within privacy, what’s private and not private. Analogously, privacy essentialism says we know there is a geographic boundary between Russia and the Ukraine, but drawing that line is subject to fierce debate. Solove’s argument boils down to there being many different lines between political entities, and it’s not just where to put that boundary line that is debatable but whether that boundary falls under the umbrella of the term “privacy.” Furthering the analogy, what is the boundary between the United States federal government and individual states or even tribal nations. Now we’re not talking about geographic boundaries but jurisdictional ones. Solove, in his bottom-up taxonomy, aimed to identify “privacy problems that have achieved a significant degree of social recognition.” In other words, what boundaries are we even talking about in this umbrella term? This meta-boundary setting problem (what do we set as the boundaries up for discussion that we then need to set) is a fatal downfall of Solove’s Taxonomy, according to Angel & Calo (2023). We can’t properly discuss privacy until we have a unified definition of privacy, they say, because Solove’s approach risks encroaching on too many other fields of analysis (such as consumer protection, discrimination, etc.)
Engineers, though, are ever pragmatic. Talking about “privacy” is unhelpful in privacy engineering. I can’t translate a philosophical construct into actions. Solove’s Taxonomy helps break this ambiguous lofty term into discrete digestible activities that can be identified and acted upon. Telling an engineer to solve privacy is about as useful as telling them to solve health. They need something more concrete (solve an arrhythmic heart). Telling them that it may be problematic when data is collected over time or from multiple sources (potentially the harm of aggregation, under the taxonomy), now they can start developing a solution. Once the potential aggregation points are identified, engineers can build in controls: minimize data coming into the system (less data, less data to aggregate), obfuscate the data (making it harder to combine into profiles of individuals), or get informed authorization from individuals and through the “magic of consent” turn a harm into a service (“click this button and we’ll gather up all references to your on the web and write your profile for you!”).
Angel and Calo’s criticism of social recognition of privacy harms, though, is spot on in one regard. When does the combining of data sources reach the threshold of the harm of “aggregation?” Who decides that the aggregation of data, something that information rich companies do persistently, is even a normative harm (i.e. violates social norms)? Who is the authority designating this a “harm?” This is something that I struggle with in my consulting business with clients. In training, I can give copious examples of where society expresses disgust for aggregation, using, as Solove did, in his original paper, “historical, philosophical, political, sociological, and legal sources.” I can cite Alan Westin’s opinion piece in the New York Times in March 1970:
“Retail Credit [Corporation’s] files may include ‘facts, statistics, inaccuracies and rumors’ … about virtually every phase of a person’s life; his marital troubles, jobs, school history, childhood, sex life, and political activities.”….“Almost inevitably, transferring information from a manual file to a computer triggers a threat to civil liberties, to privacy, to a man’s very humanity because access is so simple.”
Now known as Equifax, Retail Credit Corporation’s creation of vast dossiers on Americans and the social disdain of their practices, led to the passage of the Fair Credit Reporting Act (FCRA), one of the earliest consumer privacy laws. Upon learning this, many people are shocked. The day to day operations of privacy programs obfuscates this rich history of why we have privacy programs and privacy laws. The need to support these discussions on the social norms of privacy and its history led me to create the volunteer driven Privacy Wiki, a site dedicated to cataloging hundreds of news stories of “privacy problems” organized, of course, by…. drum roll please… the Solove Taxonomy.
What I’ve ultimately settled on though is that it is the clients’ prerogative as to what harms they are willing to recognize. Many focus on the information processing and dissemination harms, owing to the outsized influence of data protection laws. More recently, a recognition that the manipulative interfaces and deceptive designs call for deeper introspection of points of “decisional interference” in consumer engagements. But, ultimately, they decide what they are going to address. This is part of the reason the Institute of Operational Privacy Design’s (IOPD) Design Process Standard calls for organizations to adopt and specify their own risk model. It’s a very real realization that no organization, currently, is going to address every privacy harm. It’s a matter of prioritization and risk management. Frankly, it’s a win if organizations even define their risk model, which few do. Similarly, in the IOPD’s forthcoming standard for products and services, while the institute is more prescriptive about the risk model, organizations applying the standard can still selectively specify which risks are in scope and which not, again owing to the realization that prioritization will inevitably leave some harms out of consideration.
Angel & Calo’s (2023) further criticism of the taxonomic approach addresses the lack of resolution between privacy-privacy conflicts. Another point I’ve seen play out first hand. How do you prioritize two competing claims? This is no easy problem to solve and, in fact, the IOPD’s subcommittee on Privacy by Default struggled to come up with an answer. When the configurability of a system only impacts one issue for one person, the default configuration is a no brainer. The default should be the less harmful, less risky option. But what happens when flipping a switch decreases one privacy harm only to increase another? What if turning on caller-id exposes the caller’s phone number but allows the recipient to avoid unwanted intrusions? Should the default be the caller-id is suppressed to protect the confidentiality of the caller but now the recipient is unable to avoid undesired calls? You may fall on one side or the other, but hopefully you’ll admit there is an argument to be made from both perspectives. Angel & Calo (2023) argue that a unified theory of privacy would help resolve these conundrums, but I see no evidence to support that. Ultimately, the IOPD decided, for their forthcoming standard, that rather than try to resolve this broadly and generically in the standard, applicants will need to construct an argument as to why they choose the default they did and back that up by evidence such as surveys showing nobody cares about caller confidentiality and everyone hates intrusive callers.
Ultimately, I find Solove’s Taxonomy useful in practice. In a sea of talks about addressing “privacy issues,” solving “privacy problems,” improving “privacy,” reducing “privacy risk,” the taxonomy can provide a grounding in more specific, more concrete activities that can be examined and addressed.
The author is president of the Institute of Operational Privacy Design, which is leading the way in creating practical and thoughtful leadership in the privacy engineering space. Our forthcoming standard on privacy by design and default will be available in draft months before being open for public comment. To get you or your company involved, consider joining. Lifetime membership is only available through 2024 year end.
[In July 2023, Kim Wuyts and Isabel Barbera invited me to present the keynote talk to the International Workshop on Privacy Engineering in Delft, Netherlands. Subsequent to that, and because we felt there wouldn’t be an overlapping audience, Nandita Narla and Nikita Samarin, invited me to give the same talk to another group of privacy engineers at the PEP23 workshop ahead of SOUPS in Anaheim, CA. For those who couldn’t be there at either event, I decided to write this blog post to summarize my talk.]
In September of 2013, I authored a blog post for the International Association of Privacy Professionals entitled “Is 2013 the year of the privacy engineer?” The post came after myself and Stuart Shapiro provided two early workshops on privacy engineering to crowds at IAPP conferences that year and just months before our seminal paper on Privacy Engineering co-authored with, at the time, Information and Privacy Commissioner of Ontario Canada, Ann Cavoukian. The IAPP blog laid out a basic argument that addressing privacy issues needed to move out of legal departments and into engineering. Clearly, my prognostication was premature as to actual industry action, which still prefers legal solutions over technical ones. What about 2023, though? Is it finally time for the ascendence of the privacy engineer?
Before we can answer this question, we need to explore a bit about the concept of privacy engineering. Just a few weeks ago the IAPP published an infographic “Defining Privacy Engineering.”
The publication was the culmination of my push, while a member of the IAPP’s Privacy Engineering Advisory Board, to advocate for rigorous construction of the field. My concern was the term being diluted and applied to anything “technical” in the field of privacy. Anecdotal evidence suggested many lawyers and privacy analysts were deeming any type of coding or technical implementation as “engineering.” This led to bloggers and journalists also applying the engineering moniker to those doing the technical aspects of privacy based on what they were learning from the privacy professionals of the day.
A feedback loop ensued! Privacy professionals reading those blogs and articles similarly referred to technical privacy folks as engineers. Even those doing technical work started referring to themselves as privacy engineers, a form of self-selection bias, which only added fuel to the cycle. Of course, compounding this are job descriptions, which, despite being labeled as “privacy engineer” could just as easily fall under the title of “analyst,” “technologist” or some other non-engineering role. During my exploration of this topic, I found that HR departments at large not-to-be-named tech companies often require the engineering department to hire an “engineer” thus leading to an explosion of engineering roles with no engineering duties (“public relations engineer”, “finance engineer”, etc.)
This debate (“who is the true engineer”) that I’m putting forward is reminiscent of one from my childhood, the question of who is a punk and who is a poseur (aka, a suburbanite who spikes their hair on the weekends but doesn’t live the lifestyle of punk). Though I don’t recall the intensity of the debate at that time, in 1985 MTV (back when they played music and not 24 hours of Ridiculousness) put out a documentary on the LA punk scene entitled “Punks & Poseurs” which suggested the question was one of massive scrutiny within the subculture.
Lest you think the punk/privacy connection is fleeting, I present exhibit two into evidence: the color similarities of the album cover for the Exploited’s Punks Not Dead and CMU’s privacy engineering program logo “Privacy is Not Dead.”
While I don’t think any privacy engineers are going around beating up faux privacy engineers, the debate is worth having, in my opinion, and potentially more important to those relying on the services of such engineers. So let’s stage dive into the discussion:
What is Engineering?
There are a few authoritative definitions of engineering, but I like this one from the Accreditation Board for Engineering and Technology: “The profession in which a knowledge of the mathematical or physical sciences gained by study, experience and practice is applied with judgement to develop ways to utilize, economically, the materials and forces of nature for the benefit of mankind.” Applying this to privacy, it seems fairly logical that privacy takes the role of the “benefit of mankind.” I think the primary gist of what distinguishes an engineer from say an analyst or other professional working in the area is the application of knowledge of mathematical or physical sciences.
I’d like to analogize this to bridge building. You can design and build a bridge without “engineering” that bridge. However, you may end up with a bridge that collapses, as the Tacoma Narrows Bridge did in 1940. In response, a builder could naively suggest a stronger bridge, better materials, or more pillars, but it takes the analysis of an engineer, applying the mathematical and physical sciences, to determine the problem of aerolastic flutter and engineer a solution.
Another analogy I like comes from the realm of software engineering. Programming students are often given the task of sorting lists. Invariably, they produce a sorting program that compares all elements of the lists to every other element. Those who have more study in proper design of sorting algorithms know that this is inefficient, requiring, at worst, n times n passes (where n is the number of elements on the list). More efficient sorting algorithms exist such as “merge sort.” Other sorting algorithms can take advantage of qualities of the elements being sorted to be even more efficient. These are often described using big O notation, where O means on the order of. Inefficient algorithms, as just described, are usual O(n2) and more efficient ones are O(n log n). Hence, the study of big O notation and algorithms distinguishes the engineering of software versus the programming of software. Both an engineer and a programmer may write software to result in sorting a list, but the engineer has developed a more efficient program by applying the study of mathematics and science to optimize the resources of the computer.
Unlike bridge engineering or software engineering, privacy engineering actually encompasses several different domains. In this way, it’s more similar to, say, safety engineering, where the quality being achieved (safety or privacy) can be desired in many distinct applications.
We can think about safety as a desired quality in the aforementioned bridge engineering, but also in industrial machine design, tool safety, food handling equipment, medical equipment, and many other fields. Someone designing safety into a bridge will not use the same skills and resources as someone building safety in food handling, though they will still have the generic application of math and science to solving the problem. Similarly, privacy engineering is an umbrella covering different disciplines. As part of the aforementioned attempt by the IAPP to define privacy engineering, the advisory board identified a non-exhaustive set of domains where you might apply different engineering techniques to build in privacy.
Software Engineering: This is what most people think about when thinking of privacy engineering. Software engineering covers the design and development of software and building in privacy during the collection, processing and sharing of data. The engineering comes into play during considerations of the tradeoffs of efficiency, utility and risks to individuals.
IT Architecture: When you combine multiple IT components (which may be software engineered), you may get emergent properties or exacerbate risks that were negligible in their individual components. IT Architecture includes considerations of protocols and interfaces between components, again optimizing between efficiency, utility and risks.
Data Science: Privacy in data science concerns the risks from data sets, combinations of data, inferences and such without consideration of the specifics of software collecting, processing or sharing that data. Data science for privacy often involves investigating identifiability of data or linkability between data sets.
HCI/UI-UX: It’s not all about the data. Many privacy harms occur during the interactions between individuals and computers. Spam, pop-up ads and other intrusions are a form of invasions into ones personal space. Manipulative designs may interfere with individuals’ autonomy and decision making. The study of Human Computer Interactions can make use of behavioral economics, psychology and other scientific analysis to minimize these privacy harms.
Business Processing Engineering: Business process engineering traditionally covers the design of efficient business processes. Think industrial manufacturing, though it can be applied to more white-collar business processes like HR and Marketing. While efficiency of resources is the primary goal of business processes, they can be designed to improve privacy as well. This is a nascent area of development, but one worth watching.
Physical Engineering: While there are few, if any, self-identified privacy engineers working in physical spaces, privacy has been a design consideration in the physical world for as long as there have been eaves to stand under. Not only in private spaces in homes, but hospitals are also a frequent target for privacy design. But what about engineering? There is increasing opportunity for physical engineering for privacy in regard to IOT devices, both in their design and the design of spaces to prevent ubiquitous surveillance by those devices.
Systems Engineering: This is my primary area of work. Systems engineering considers the interconnectedness of all of the above: cyber-physical-social systems and the interactions and interfaces between them and individuals. Systems engineering looks at narrow risks, risk from emergent properties, cascading risks between system elements and tradeoffs of privacy with other quality and functional system requirements.
Next Steps for Privacy Engineering
As you can see, privacy engineering covers a wide swath of different domains. Besides the generic desire for more privacy, what cross-discipline language can we seek to define similarities? I think we can draw upon the analogous safety engineering for guidance. What are safety engineers trying to do? They are attempting to reduce risk, to make products or service safer by reducing the likelihood of harmful events and the level of harm when those events occur. Similarly, privacy engineers need to focus on reducing privacy risk, the likelihood of privacy events and impacts of those events. [Note, if you’re thinking data breaches, you and I need to have a talk. Privacy is not security, but I won’t derail this blog post with a privacy versus security risks deep dive.]
Privacy risk research is still in its early development. Significant research still needs to be done into quantifying privacy risk, creating feedback loops to incorporate real world data back into risk analysis, measuring the effectiveness of controls on risk and producing ways of determining reasonable levels of risk tolerance. In addition there needs to be more work to tie controls to risk. Privacy professionals have worked for years at developing various technical and organizational controls meant to improve privacy. However, scant work has been done to tie those controls to actual risk reduction. It’s as if bridge engineers said using high-tensile steel improves bridge safety and had tons of data and science backing up the resilience and breakpoints of the steel. That statement seems logical but lacks measurable risk reduction. While you may measure the tensile strength of the steel, that’s different than measuring use of that steel in a particular design’s effect on risk. Similarly, there are many measures, metrics and KPIs for privacy, but what does the ε in differential privacy translate into as to whether a real threat actor is likely to attempt to re-identify the patient in a doctors office’s prescription for 325 mg of acetaminophen?
There also needs to be a causal connection between controls and risk reduction. Increasing the tensile strength of the steel in a bridge isn’t going to reduce risk if the weak point is the connection to the earth. Bridging this gap is what the Institute of Operational Privacy Design (IOPD) is working on in our newest standard. The IOPD is attempting to use structured assurance cases, something used in safety engineering, in privacy. The idea is that you state a claim, such as “This privacy risk has been mitigated” then make an argument as to why it should be considered mitigated. Finally, you provide evidence to support this argument. Lawyers should like this, because it’s similar to a legal argument, showing why some evidence supports some legal claim.
If you haven’t read the book, Moneyball: the Art of Winning an Unfair Game, or seen the movie staring Brad Pitt and Jonah Hill, I highly encourage you to see them out. I tend to be a “privacy” subject matter expert, but one of the most important aspects of that expertise is the ability to consume diverse content from other expects and apply it to the world of privacy. Whether its behavioral economics (from sources like the Freakonomics and Hidden Brain podcasts), how people learn (from YouTube channel Vertasium), or use of statistics and probability in baseball (i.e. Moneyball).
I see a huge parallel between Baseball management in the pre-2000 era and the privacy management today. For a hundred plus years, Baseball team management was governed by intuition. Managers and scouts thought they knew what made up a good team. Baseball statistics were published for decades, but wasn’t used in a way that really optimized team performance. The concept of Sabermetrics (the empircal analysis of in game acitivity) began in the 1960s, grew in 1970s, but then transformed the business of Baseball in the 2000s (as chronicled in the book and movie; also see this podcast). Sabremetrics took the “intuition” out of Baseball and turned it into a science, one based on statistics and probability. Science can’t tell you a particular batter will hit a home run against a particular pitcher, but probability can show that you, if you make the same choices, game after game, you’re going to end up with result in a certain range.
Similar transformations have hit other industries. I believe, the privacy profession is in line for this sort of refactoring. Attempts have been made for decades to create KPI (Key Performance Indicators) for privacy. One of my earliest introductions was a talk by Tracy Ann Kosa at an IAPP conference about a decade ago. But most privacy program KPIs, in my opinion, still follow the Baseball analogy. Scouts were looking at player stats, but ultimately they were looking at the wrong statistics to determine game outcome. As Jonah Hill says in the movie, “Your goal is not to buy players, its to buy wins.” The privacy profession has, for its short life, relied mostly on heuristics, shortcuts that we intuitively sense, improve desired outcomes. Those shortcuts (such as GAPP, FIPPs, Principles, etc.) have become goals themselves and the metrics tied to those intermediary goals. But, like Baseball, the goal is not the player, the goal is the game. Analogously, a goal in privacy is not transparency, but rather whether a person has the ability to make decisions about things that affect them (with full knowledge and without being overwhelmed). Transparency is a sideshow. Transparency is worthless if it overwhelms or doesn’t support meaningful decision making.
The point of this post is that metrics are important, rigorously important. Privacy needs to step out of the dark ages of intuition, superstition, and old wives tales.
The author is principal at Enterprivacy Consulting Group, a boutique consulting firm focused on privacy engineering, privacy by design and the NIST Privacy Framework.
International data transfer is probably one of my least favorite privacy exercises. Why? Probably my main dislike deals with the fact that its not really about privacy, but often more about protectionism. That being said, data transfers are a hot hot topic these days, both in Europe and in countries like China and Brazil. It wasn’t until recently that I realized if you look at GDPR from far away, you see there are really four key chapters
Chapter II – Principles
Chapter III – Rights of the Data Subject
Chapter IV – Controllers and Processors
Chapter V – Transfers
Fundamentally, most people, myself included, equate GDPR to principles of data processing, rights afforded the data subject and obligations of controllers and processers, but right up there with those key concepts is a whole chapter on international data transfers. At least in the minds of the GDPR authors, transfers are clearly not an afterthought but one of the four major components of the regulation.
With data transfers clearly an important element of GDPR, its important that the analysis of transfers be done with some care. I, for one, am a very visual person. I can analogize concepts visually much easier than verbally. Astute readers may have noticed the diagrams accompany my previous post on data transfer regarding the recent draft guidelines put out by the European Data Protection Board. In working through data transfer scenarios, I’ve found it extremely helpful to illustrate or diagram them.
Disambiguating “transfers” and “transmission” of data
Before diving into how to diagram data transfers, it’s important to distinguish the terms transfer and transmit. Transmission of data occurs when data goes from one place to another. If I send you an email with an attachment, I am transmitting data to you. That data is transmitted over multiple servers, through different service providers and maybe through different geographies. A transfer, however, under the GDPR is a legal chain by which a controller or processer transfers data to another controller or processor. In other words the transmission ≠ the transfer.
Perhaps an example would help. I use Dreamhost to host my website. On my website, I host a file (say a pretty infographic). You go to my website and download the file. The file is transmitted from Dreamhost (wherever their servers are) to you (wherever you are) However, there is not a legal transfer from Dreamhost to you. The transfer was from me to you. I may never have even had the file in my possession. Let’s illustrate that.
Simple transfer/transmission diagram
As you can see, I’ve used dotted lines to illustrate the transmission of data, the 0’s and 1’s flying over the internet from DreamHost to You. But the transfer, the metaphysical or conceptual transfer, from me to you, is illustrated with a solid line. Let’s look at an EU example.
European Union data transfers
EU data transfer diagram
Here, ChairFans, GmbH, a German company, sends a file to Star Analytics, Inc., in the US, to analyze. In this case the transmission is parallel to the transfer. ChairFans is transmitting data to Star Analytics and they are also transferring that data. Remember, the transmission refers to the physical bits flying across the Atlantic Ocean and the transfer refers to the act of one entity giving the other entity the data. If you’re still struggling, you can think of it this way. If a hacker broke into ChairFans and stole the data, the data would still be transmitted over the internet across the Atlantic Ocean, but ChairFans didn’t “transfer” data to the hacker. It was not a deliberative, intentional act of making the data available to the hacker.
Do we need a GDPR Chapter V transfer tool for this transfer? If there was
Diagramming
To diagram data transfers, I’m using diagrams.net, a free (and privacy friendly) tool to create diagrams. I’ll provide the file for all these diagrams at the end of this blog. I’ve also included a template for the shapes I’m using, which you can use to create your own data transfer diagrams. For the following example, I’m first going to illustrate the Use Case for supplementary measures in the EDPB Recommendations.
EDPB Recommendation
Use Case 1: Data storage for backup and other purposes that do not require access to data in the clear
A data exporter uses a hosting service provider in a third country to store personal data, e.g., for backup purposes. Notice, I’ve now added the labels, Exporter and Importer to the entities.
Illustration 3
Use Case 2: Transfer or pseudonymised Data
A data exporter first pseudonymises data it holds, and then transfers it to a third country for analysis, e.g., for purposes of research. This really isn’t distinguished from the previous example. I’ve added a gear icon to indicate the pseudonymization.
Illustration 4
Use Case 3: Encrypted data merely transiting third countries
A data exporter wishes to transfer data to a destination recognised as offering adequate protection in accordance with Article 45 GDPR. The data is routed via a third country.
Illustration 5
Use Case 4: Protected recipient
A data exporter transfers personal data to a data importer in a third country specifically protected by that country’s law, e.g., for the purpose to jointly provide medical treatment for a patient, or legal services to a client. No different than illustration 3
Use Case 5: Split or multi-party processing
The data exporter wishes personal data to be processed jointly by two or more independent processors located in different jurisdictions without disclosing the content of the data to them. Prior to transmission, it splits the data in such a way that no part an individual processor receives suffices to reconstruct the personal data in whole or in part. The data exporter receives the result of the processing from each of the processors independently, and merges the pieces received to arrive at the final result which may constitute personal or aggregated data.
Illustration 6
Use Case 6: Transfer to cloud service providers or other processor which require access to data in the clear
A data exporter uses a cloud service provider or other processor to have personal data processed according to its instructions in a third country.
Illustration 7
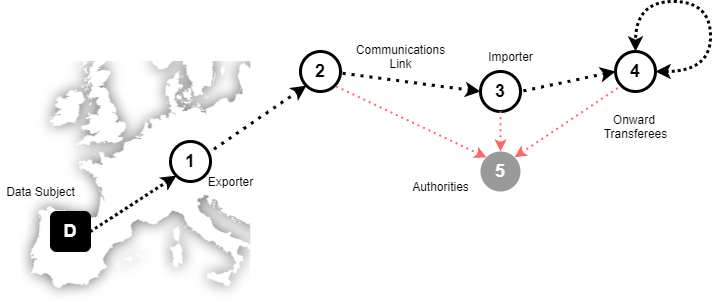
Use Case 7: Remote access to data for business purposes
A data exporter makes personal data available to entities in a third country to be used for shared business purposes. A typical constellation may consist of a controller or processor established on the territory of a Member State transferring personal data to a controller or processor in a third country belonging to the same group of undertakings, or group of enterprises engaged in a joint economic activity. The data importer may, for example, use the data it receives to provide personnel services for the data exporter for which it needs human resources data, or to communicate with customers of the data exporter who live in the European Union by phone or email. Here I’ve added an IT system to indicate that the Common Enterprise has remote access to that IT system.
Illustration 8
EDPB Guideline on Article 3 and Chapter V
Next up I’ll tackle the examples from the draft EDPB Guidelines on the Interplay Article 3 and Chapter V.
Example 1
Maria, living in Italy, inserts her personal data by filling a form on an online clothing website in order to complete her order and receive the dress she bought online at her residence in Rome. The online clothing website is operated by a company established in Singapore with no presence in the EU. In this case, the data subject (Maria) passes her personal data to the Singaporean company, but this does not constitute a transfer of personal data since the data are not passed by an exporter (controller or processor), since they are passed directly and on her own initiative by the data subject herself. Thus, Chapter V does not apply to this case. Nevertheless, the Singaporean company will need to check whether its processing operations are subject to the GDPR pursuant to Article 3(2).12
Illustration 10
Example 2
Company X established in Austria, acting as controller, provides personal data of its employees or customers to a company Z established in Chile, which processes these data as processor on behalf of X. In this case, data are provided from a controller which, as regards the processing in question, is subject to the GDPR, to a processor in a third country. Hence, the provision of data will be considered as a transfer of personal data to a third country and therefore Chapter V of the GDPR applies. Note, I’ve added the labels C and P to indicate Processor and Controller
Illustration 9
Example 3: Processor in the EU sends data back to its controller in a third country
XYZ Inc., a controller without an EU establishment, sends personal data of its employees/customers, all of them non-EU residents, to the processor ABC Ltd. for processing in the EU, on behalf of XYZ. ABC re-transmits the data to XYZ. The processing performed by ABC, the processor, is covered by the GDPR for processor specific obligations pursuant to Article 3(1), since ABC is established in the EU. Since XYZ is a controller in a third country, the disclosure of data from ABC to XYZ is regarded as a transfer of personal data and therefore Chapter V applies.
Illustration 10
Example 4: Processor in the EU sends data to a sub-processor in a third country
Company A established in Germany, acting as controller, has engaged B, a French company, as a processor on its behalf. B wishes to further delegate a part of the processing activities that it is carrying out on behalf of A to sub-processor C, a company established in India, and hence to send the data for this purpose to C. The processing performed by both A and its processor B is carried out in the context of their establishments in the EU and is therefore subject to the GDPR pursuant to its Article 3(1), while the processing by C is carried out in a third country. Hence, the passing of data from processor B to sub-processor C is a transfer to a third country, and Chapter V of the GDPR applies.
Illustration 11
Example 5: Employee of a controller in the EU travels to a third country on a business trip
George, employee of A, a company based in Poland, travels to India for a meeting. During his stay in India, George turns on his computer and accesses remotely personal data on his company’s databases to finish a memo. This remote access of personal data from a third country, does not qualify as a transfer of personal data, since George is not another controller, but an employee, and thus an integral part of the controller (company A). Therefore, the disclosure is carried out within the same controller (A). The processing, including the remote access and the processing activities carried out by George after the access, are performed by the Polish company, i.e. a controller established in the Union subject to Article 3(1) of the GDPR.
Illustration 12
Example 6: A subsidiary (controller) in the EU shares data with its parent company (processor) in a third country
The Irish Company A, which is a subsidiary of the U.S. parent Company B, discloses personal data of its employees to Company B to be stored in a centralized HR database by the parent company in the U.S. In this case the Irish Company A processes (and discloses) the data in its capacity of employer and hence as a controller, while the parent company is a processor. Company A is subject to the GDPR pursuant to Article 3(1) for this processing and Company B is situated in a third country. The disclosure therefore qualifies as a transfer to a third country within the meaning of Chapter V of the GDPR.
Illustration 13
Example 7: Processor in the EU sends data back to its controller in a third country
Company A, a controller without an EU establishment, offers goods and services to the EU market. The French company B, is processing personal data on behalf of company A. B re-transmits the data to A. The processing performed by the processor B is covered by the GDPR for processor specific obligations pursuant to Article 3(1), since it takes place in the context of the activities of its establishment in the EU. The processing performed by A is also covered by the GDPR, since Article 3(2) applies to A. However, since A is in a third country, the disclosure of data from B to A is regarded as a transfer to a third country and therefore Chapter V applies.
Illustration 14
My comments to the EDPB
Subsequent to the draft guidelines above, I made a comment to the EDPB on two scenarios they should cover. Those scenarios are detailed below.
A data subject contracts with X, GmbH (in Germany) which is a European Union based subsidiary of X, Inc (in the United States). However, the data subject never actually supplies personal data to X, GmbH as the data subject directly transmit data to X, Inc. in the United States. This is a Chapter V transfer of data requiring a transfer tool. X, GmbH and X, Inc. use standard contractual clauses in place governing the transfer of data. X, GmbH is the exporter and X, Inc. is the importer.
Illustration 15
ABC, GmbH (in Germany) instructs employees to use a service provided by X, Inc., in the United States. Employees’ behavior is tracked via the service provided by X, Inc, thus X, Inc. is subject to GDPR for the data under Article 3.2(b). Because ABC, GmbH is “mak[ing] personal data, subject to this processing, available to…” X, Inc. via instructions to its employees, there is a transfer of data under Article V. ABC, GmbH and X, Inc. execute the standard contractual clauses with ABC, GmbH as the exporter and X, Inc. as the importer.
Illustration 16
I posed this scenario on LinkedIn
Company X, GmbH (DE) host data on an Australian data server. They contract with Company Y, Inc. in the United States to process data. Company Y’s employee working remotely in Australia, accesses the data on the data server. X, GmbH and Y, Inc. execute Standard Contractual Clauses to govern the transfer. There is a legal transfer of data because X, who has putative control over the data in Australia, gave access to Y, who has putative control over it’s employee in Australia. This despite the fact that the data never left Australia.
Illustration 17
If you want to explore these scenarios and make some of you’re own, download this file (be sure to right click and save the file to your desktop). Then go to https://diagrams.net then open the file from there.
Below are my comments on recent EDPB Guidelines which I’m submitting as part of their public consultation.
The guidelines need to provide an example which is a very common scenario:
A consumer data subject (located in the EU) registers with an online service. The service is being offered by a company in a third country, thus placing the company under the territorial scope of GPDR via Art. 3.2(a). However, when registering for the service, the data subject enters into an agreement with a subsidiary of the company located in the EU. For avoidance of doubt, the subsidiary in the EU, never possesses personal data of the data subject. It appears, in this scenario, that there is a legal “transfer” from the subsidiary in the EU to the parent company in the third country.
Example I
Illustration of data transmission and a legal data transfer
In the example illustrated above, a data subject contracts with X, GmbH (in Germany) which is a European Union based subsidiary of X, Inc (in the United States). However, the data subject never actually supplies personal data to X, GmbH as the data subject directly transmit data to X, Inc. in the United States. This is a Chapter V transfer of data requiring a transfer tool. X, GmbH and X, Inc. use standard contractual clauses in place governing the transfer of data. X, GmbH is the exporter and X, Inc. is the importer.
A similar scenario exists when a business in the EU directs its employees to use an app (such as for Human Resource purposes) which is provided by a vendor in a third country which monitors the behavior of the employees (such as job time tracking), thus subjecting the vendor to GDPR under Art 3.2(b). Even though the employer never holds the data, this still appears to be a transfer under the guidance (“otherwise makes personal data available”). A clarifying example in the guidelines be helpful.
Example II
Illustration of a data transmission and legal data transfer
ABC, GmbH (in Germany) instructs employees to use a service provided by X, Inc., in the United States. Employees’ behavior is tracked via the service provided by X, Inc, thus X, Inc. is subject to GDPR for the data under Article 3.2(b). Because ABC, GmbH is “mak[ing] personal data, subject to this processing, available to…” X, Inc. via instructions to its employees, there is a transfer of data under Article V. ABC, GmbH and X, Inc. execute the standard contractual clauses with ABC, GmbH as the exporter and X, Inc. as the importer.
In the fall of 2020, I went on a wonderful, adventurous, hike down from the rim of the Grand Canyon into Phantom Ranch on the river. The trip was arduous and the climb out was tough given my hailing from the vertically challenged state of Florida. Prior to this undertaking, I had begun training, in Florida, including perhaps Florida’s most vertical trail, the Torreya Challenge in Torreya State Park. After this adventure and the two months of training leading up to it, I became a bit of a couch potato in December and January. About the middle of January, I decided to do something about that. Seeing all the wonderful trails in my area, I set myself a challenge, to hike or bike 90 different trails in 100 days. I gave myself a hundred days to account for weather, work or other impediments to doing a trail each day.
Previous
Next
Now you may be asking, what this has to do with privacy. The short answer is not much, but there is always an angle. In using AllTrails, the trail mapping application, I discovered a nifty way to stalk people. See my previous blog post for more.
In February, thanks to Publix Supermarkets, I procured a large amount of trail mix. By the end, despite adding some more in March and April, I was down to one container.
My typical kit consistent of day pack with water reservoir, bear bell, bear mace, Chapstick, headphones to listen to Privacy podcasts, snacks (not pictured trail mix), and trail maps. Also not pictured are optional sunscreen and insect repellent.
Off I set on January 30th. The task seemed simple but, as with many things, implementation was more fraught than at first imagined. I tried to do longer trails or those farther away when I had more time (like weekends) or during nice weather. One early trail, Pond Loop, at Okeeheepkee Prairie County Park, I completed on a rainy afternoon was only 0.5 miles. I decided after that to only include trails over 1 mile long. This lead me to a few times combining short trails into one “trail” or stretching a trail to it’s extreme (exploring every nook and cranny) to try to get that mile in. Trying to define a “trail” also led to some creative interpretations. Not all trails are simply laid out in the platonic idealized state. Some are based on forest service roads, some intersect and loop and figure 8. Some are out and back, retracing your steps. I had to break some long trails, like the 30+ miles of the St. Marks trail into more manageable pieces of about 16 mile chunks (8 out and 8 back). Some of my trips weren’t trails at all, but I counted them, like when I walked 6 miles home after dropping off a truck at the rental car company. I learned about new trails, which weren’t easily found, like the Capital to Coast trail still under construction, which when fully complete with be 120 miles of biking or shared use paths from Tallahassee to the Emerald coast.
It was perhaps the best time to be out hiking and biking in Florida. Spring weather meant it wasn’t too hot, the parks were green and flowers were in full bloom. I saw so many animals, many that your rarely see as a weekend warrior. In addition to the usual squirrels and lizards, I saw a bobcat, a family of boar, water moccasins and other snakes, a mole, a red pileated woodpecker, a gopher tortoise, giant mosquitoes, ticks, spiders, and many more. I did not, however, see a bear. Not to say they weren’t there, but ever since I encountered a bear last year, I’ve been hiking with a bear bell and bear mace, so they’ve thankfully kept their distance.
What lurks beneath? Creature from the black lagoon? Manatee? Large alligator? Something was moving fast and leaving a wake under the Crooked River in Tate’s Hell State Forest.
As a capstone to my challenge, I returned to Torreya State Park to take on the Torreya Challenge. It was a wonderous exhausting 4 hours which left me with a terrible head ache, but I made it. 90 different trails. 98 days in the making. 478 miles covered. Challenge complete. Level UP!
More Galleries
Animals and InsectsFlora and FungiDoll’s Head TrailGeorgiaEconfina State ParkEmerald CoastTorreya State Park – Torreya Trail and the Torreya Challenge TrailPanoramas
#
Location
Trail
Miles
Type
Links
1
Lake Talquin State Forest – Lines Track
West Loop
3.8
Hike
2
Ellinor Klapp-Phipps Park
West Loop
2.9
Hike
3
J.R. Alford Greenway
Bluebird Loop
3.9
Hike
4
San Luis Mission Park
San Luis Park Loop
1.98
Hike
5
Apalachicola National Forest
GF&A Trail
5
Hike
6
Maclay Gardens State Park
Shared Trail Loop
5.5
Bike
7
Lake Talquin State Forest – Lines Track
Talquin Loop (Blue)
6
Bike
8
Okeeheepkee Prairie County Park
Pond Loop
0.5
Hike
9
Apalachicola National Forest
Munson Hills
8.4
Bike
10
Governors Park
Fern Trail
3.4
Hike
11
Three Rivers State Park
Eagle Trail
3
Bike
12
St Marks Trail
North Trail
16
Bike
13
Ochlockonee River WMA
Old Cemetary Rd
3.9
Hike
14
Lafayette Heritage Trail Park
Lafayette Heritage Trail
6.9
Hike
15
Wakulla Springs State Park
Wakulla Springs Park Trail
10.1
Hike
16
Orchard Pond
Orchard Pond Trail
6.9
Bike
17
Silver Lake Recreation Area
Silver Lake Habitat Trail
1.4
Hike
18
Timberlane Ravine Nature Preserve
Timberlane Ravine Nature Trail
1.5
Hike
19
San Felasco Hammock Preserve State Park
Moonshine Creek Trai
1.6
Hike
20
Lakeland Highlands Scrub
Lakeland Highlands Scrub Trail
3.1
Hike
21
Catfish Creek Preserve State Park
Campsite 2 White Trail
5.5
Hike
22
Black Creek Preserve
Red Trail
4.9
Hike
23
Tom Brown Park
Magnolia MTB Trail
3
Bike
24
Central Park
Central Park Lake Loop
1.9
Hike
25
Apalachicola National Forest
Camel Lake Loop
8.2
Hike
26
J. R. Alford Greenway
Yellow Loop
5.3
Bike
27
Miccosukee Canopy Road Greenway
Miccosukee Greenways Trail
15.5
Bike
28
Bald Point State Park
Loop
3.1
Hike
29
A.J. Henry Park
A.J. Henry Park Trails
1.9
Hike
30
Alfred B. Maclay Gardens State Park
Bike Loops
5.7
Bike
31
Wakulla State Forest
Nemours Trail
1.6
Hike
32
Ochlocknee River WMA
Cut Through Lewis Loop
2.5
Hike
33
Kolomoki Mounds State Park
Spruce Pine Trail
3.1
Hike
34
Wilson Hospice House
Wilson Hospice House Trail
1.3
Hike
35
Marjorie Turnbull Park
Trail
1.6
Hike
36
Tallahassee
Morning Hike from Budget
5.4
Hike
37
Gil Waters Preserve at Lake Munson
Trail
1
Hike
38
Bald Point State Park
Sandy Trails
4.2
Bike
39
Elinor Klapp-Phipps Park
Redbug Trails
4.6
Bike
40
Tate’s Hell State Forest
High Bluff Coastal Loop Trail
9
Bike
41
Ochlocknee State Park
Pine Bluff Trail
1.2
Hike
42
St. Joseph Island
Loggerhead Trail and Maritime Hammock Nature Trail
Its interesting how events can lead one find privacy and security vulnerabilities. I’m reminded of the old Connections show, where James Burke would connect seemingly unrelated events in human history and show how one led to another. During my Winter 2021 Strategic Privacy by Design course, the United States did a time shift known as Daylight Saving Time, an anachronism from the days of agriculture where the government thought changing the time twice a year to adjust to changing sunlight would help farmers use time more effectively. As a result of this shift, some students in Europe showed up at the end of a lecture because I had adjust my clock, but they, obviously being in Europe, had not.
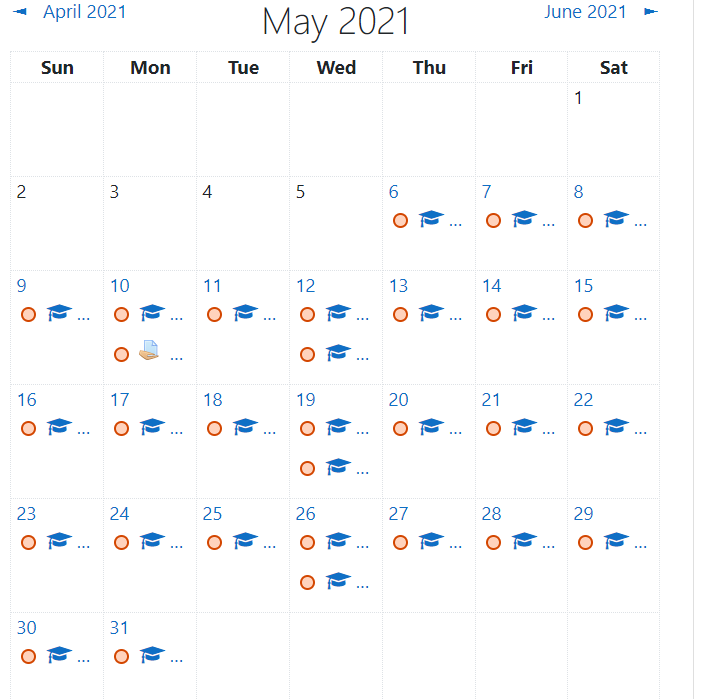
As a result of this timing error, I thought it might be good to create calendar items in Moodle (the LMS I use) for the Spring 2021 Strategic Privacy by Design course. The plan was to export the iCal file and send it to students so they would each be able to insert the important course events in their own calendar. I did just that into my calendar as well, which, unfortunately is in Google.
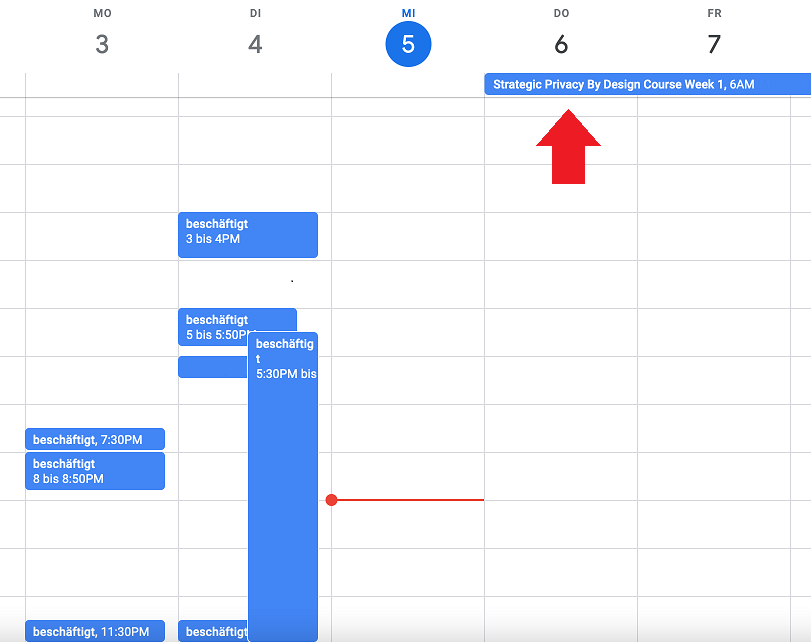
My eagle eyed assistant instructor, Maria, noticed when she was checking my schedule to send me an invite to a meeting, that should could see these items, even though I had set up to only share Free/Busy calendar (see below).
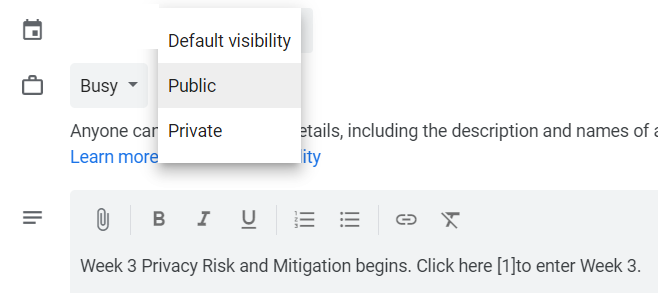
After digging around, I finally figure out what was going on. Visibility on each calendar item has options of: private, public or default visibility (meaning to default to the overall calendar’s visibility).
However, these calendar items had a class in the iCal file of public, which overrode my calendar’s default of Free/Busy only.
Those events were imported. I wanted to check, so I had my security intern invite me to three event, one she set to private, one she set to public and one she set to default visibility. As expected, despite my calendar set to Free/Busy only, the “public” event showed as public.
Your reaction may be, well this event is public, but two problems persist. 1) It still shows MY interest or possible attendance in this public event, not just whether I’m busy or free; and 2) when the sender has their calendar default to public and doesn’t realize that but sends you an invite to talk. I would suggest that my calendar settings should override the imported event’s settings, just to be on the safe side.
By the way, if anyone has a suggestion for a privacy friendly online calendar (so I can share my free/busy schedule), I’d appreciate hearing from you. I haven’t found a good alternative yet.
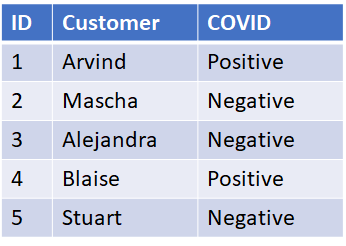
One of the potential downsides of relational data is the ease at which data can be related in both directions. A simple search of the table below will reveal not only if a known customer has COVID but a list of all COVID positive customers.
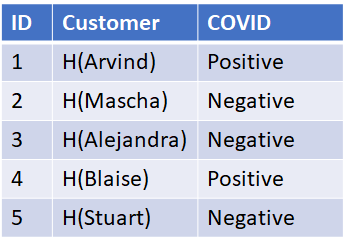
Supposed instead, you want to be able to determine if a customer has COVID but not easily obtain a list of all customers who have COVID. How might you do that? This can be accomplished using one-way functions (hashes).. By hashing the customer’s name (shown as H(name) function) and replacing that in the customer field, we no longer can get a list of customer’s with COVID. A simple SQL query will get the customer’s COVID status from their name: SELECT Covid from TABLE where Customer = hash(customer_name). The inverse, however, won’t get me the list of customers with COVID but a list of hashes: select customer from TABLE where COVID =”Positive”.
Now hashes are one way functions, meaning it’s very difficult to determine x, given H(x). However, because of the very few values of customer’s name, it’s easy to compute what’s called a rainbow table, that is a table of all possible hash values. We can then lookup the hash in the rainbow table and obtain the customer’s name for those customers that have COVID. The table below assumes we know all the names of customers, an attacker may not, but names are fairly common and even if we created our rainbow table with six thousand different common first names, that’s fairly trivial to compute.
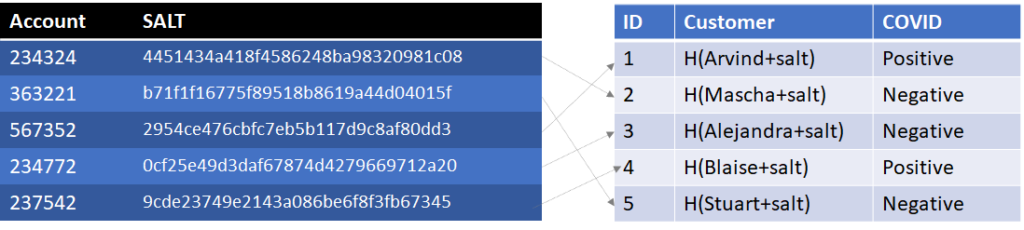
We address this with a concept called salting, which is adding a random value to the Name before hashing it, i.e. Customer = H(Name+Salt). One problem though we can’t use the same salt for every customer or an attacker could precompute a rainbow table just adding the salt to each name before calculating the hash. We also need the salt BEFORE we do the hash. Now customer’s can’t be expected to remember the salt before looking it up, but we can give them an account number, which we can relate to the salt. A customer, wanting to look up their COVID status, enters their account number and name. The system retrieves the salt using the account number and hashes the name to determine the customer and look up their COVID status. [Note, salts should be incremented with each access to prevent replay attacks but that’s beyond the scope of this blog].
Light arrows show the link between rows, only discoverable with knowledge of the customer’s name.
Now an attacker wanting to identify all known COVID cases would need to hash all the possible customer names against all the possible salts. Padding the salt table with hundreds of thousands of random account numbers could increase the number of computations necessary for the attacker. In fact, you could prefill the account table with a million rows and a million salts and randomly assign account numbers to customers. Even if two customers got the same account number, they aren’t going to get the same Customer value unless they have the same name, H(name+salt). This also benefits us because if we have two people with the same name, they could be given different account numbers and distinct COVID statuses.
In order to create a rainbow table now an attacker must hash six thousand names with a million account numbers, or 109 rows. Not impossible but starting to slow them down.
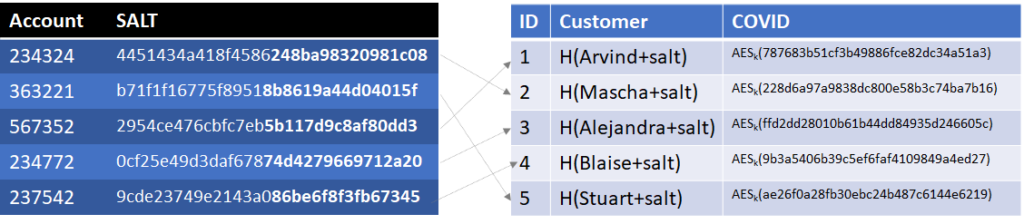
I’m going to make it even a little bit harder. Right now, we can still use the COVID table to identify how many people are COVID positive or negative. This is especially problematic if each and every customer has the same status. We can do a little encryption and steganography to hide the information. First, for each record we can generate a random 64 byte value (say 787683b51cf3b49886fce82dc34a51a2 in Hexadecimal). If we need to encode a negative result, we ensure that value has the least significant bit of 0. If we need to encode a positive result, we ensure that value has the least significant bit of 1 (i.e. 787683b51cf3b49886fce82dc34a51a3). Note the change in the last digit from 2 to 3, changing the least significant bit and the COVID status. That value is then encrypted using a symmetric cypher (such as AES) without padding or authentication to verify the accuracy of the data. We can use part of the SALT as the encryption key (bolded in the table below)
Now, an attacker can’t search the COVID table to identify how many customers have COVID. Additionally, because we used an encryption algorithm without any validation, any of the values in the COVID column will decrypt with any of the encryption keys in the account table, just with erroneous least significant bits, thus not disclosing anyone’s COVID status at all. If we used a decryption algorithm with padding or authentication, it would provide a quicker backdoor for connecting records in the account table with records in the COVID table.
One more step to slow a potential attacker down is to iterate the hashing, in other words compute H( H( H( H( …. H(name+salt))))), say 100,000 times. While slowing down lookups slightly, it significantly increases the computation of a rainbow table for an attacker, who now must compute 100,000 x 109 hashes. Increasing the number of values in the account table, increasing the potential values for name (such as using given name and surname), and increasing the number of iterations will all serve to slow an attacker down.
The concept described above is sometimes called a translucent database, such that someone who has full access to the data (a database engineer) still can’t interpret it, but with a little extra knowledge (account number and name), a customer can still retrieve their COVID status.
































 https://privacymaverick.com/wp-content/uploads/2021/05/ERGF5117.mov
https://privacymaverick.com/wp-content/uploads/2021/05/ERGF5117.mov