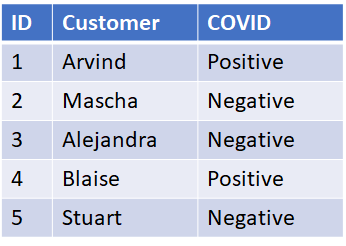
One of the potential downsides of relational data is the ease at which data can be related in both directions. A simple search of the table below will reveal not only if a known customer has COVID but a list of all COVID positive customers.
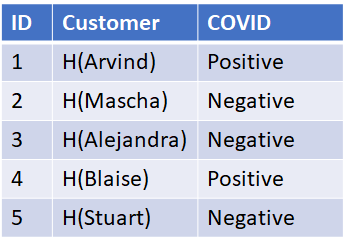
Supposed instead, you want to be able to determine if a customer has COVID but not easily obtain a list of all customers who have COVID. How might you do that? This can be accomplished using one-way functions (hashes).. By hashing the customer’s name (shown as H(name) function) and replacing that in the customer field, we no longer can get a list of customer’s with COVID. A simple SQL query will get the customer’s COVID status from their name: SELECT Covid from TABLE where Customer = hash(customer_name). The inverse, however, won’t get me the list of customers with COVID but a list of hashes: select customer from TABLE where COVID =”Positive”.
Now hashes are one way functions, meaning it’s very difficult to determine x, given H(x). However, because of the very few values of customer’s name, it’s easy to compute what’s called a rainbow table, that is a table of all possible hash values. We can then lookup the hash in the rainbow table and obtain the customer’s name for those customers that have COVID. The table below assumes we know all the names of customers, an attacker may not, but names are fairly common and even if we created our rainbow table with six thousand different common first names, that’s fairly trivial to compute.
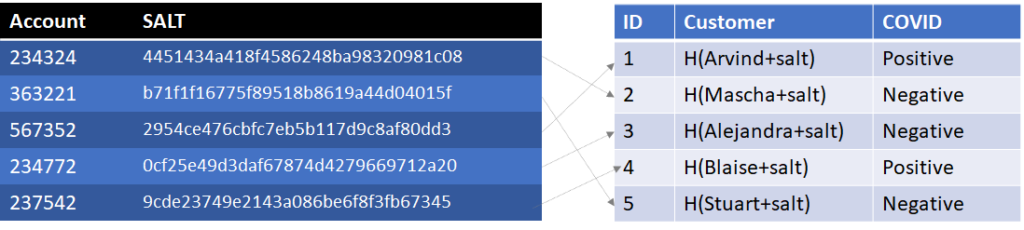
We address this with a concept called salting, which is adding a random value to the Name before hashing it, i.e. Customer = H(Name+Salt). One problem though we can’t use the same salt for every customer or an attacker could precompute a rainbow table just adding the salt to each name before calculating the hash. We also need the salt BEFORE we do the hash. Now customer’s can’t be expected to remember the salt before looking it up, but we can give them an account number, which we can relate to the salt. A customer, wanting to look up their COVID status, enters their account number and name. The system retrieves the salt using the account number and hashes the name to determine the customer and look up their COVID status. [Note, salts should be incremented with each access to prevent replay attacks but that’s beyond the scope of this blog].
Light arrows show the link between rows, only discoverable with knowledge of the customer’s name.
Now an attacker wanting to identify all known COVID cases would need to hash all the possible customer names against all the possible salts. Padding the salt table with hundreds of thousands of random account numbers could increase the number of computations necessary for the attacker. In fact, you could prefill the account table with a million rows and a million salts and randomly assign account numbers to customers. Even if two customers got the same account number, they aren’t going to get the same Customer value unless they have the same name, H(name+salt). This also benefits us because if we have two people with the same name, they could be given different account numbers and distinct COVID statuses.
In order to create a rainbow table now an attacker must hash six thousand names with a million account numbers, or 109 rows. Not impossible but starting to slow them down.
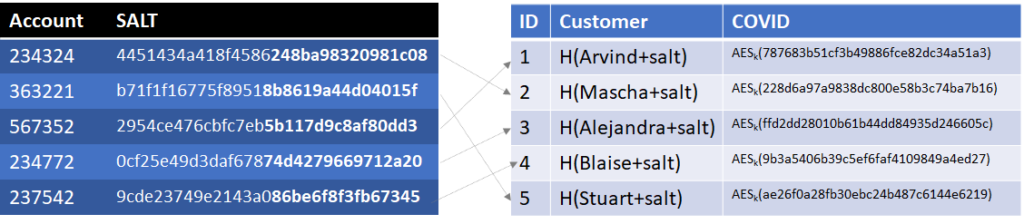
I’m going to make it even a little bit harder. Right now, we can still use the COVID table to identify how many people are COVID positive or negative. This is especially problematic if each and every customer has the same status. We can do a little encryption and steganography to hide the information. First, for each record we can generate a random 64 byte value (say 787683b51cf3b49886fce82dc34a51a2 in Hexadecimal). If we need to encode a negative result, we ensure that value has the least significant bit of 0. If we need to encode a positive result, we ensure that value has the least significant bit of 1 (i.e. 787683b51cf3b49886fce82dc34a51a3). Note the change in the last digit from 2 to 3, changing the least significant bit and the COVID status. That value is then encrypted using a symmetric cypher (such as AES) without padding or authentication to verify the accuracy of the data. We can use part of the SALT as the encryption key (bolded in the table below)
Now, an attacker can’t search the COVID table to identify how many customers have COVID. Additionally, because we used an encryption algorithm without any validation, any of the values in the COVID column will decrypt with any of the encryption keys in the account table, just with erroneous least significant bits, thus not disclosing anyone’s COVID status at all. If we used a decryption algorithm with padding or authentication, it would provide a quicker backdoor for connecting records in the account table with records in the COVID table.
One more step to slow a potential attacker down is to iterate the hashing, in other words compute H( H( H( H( …. H(name+salt))))), say 100,000 times. While slowing down lookups slightly, it significantly increases the computation of a rainbow table for an attacker, who now must compute 100,000 x 109 hashes. Increasing the number of values in the account table, increasing the potential values for name (such as using given name and surname), and increasing the number of iterations will all serve to slow an attacker down.
The concept described above is sometimes called a translucent database, such that someone who has full access to the data (a database engineer) still can’t interpret it, but with a little extra knowledge (account number and name), a customer can still retrieve their COVID status.
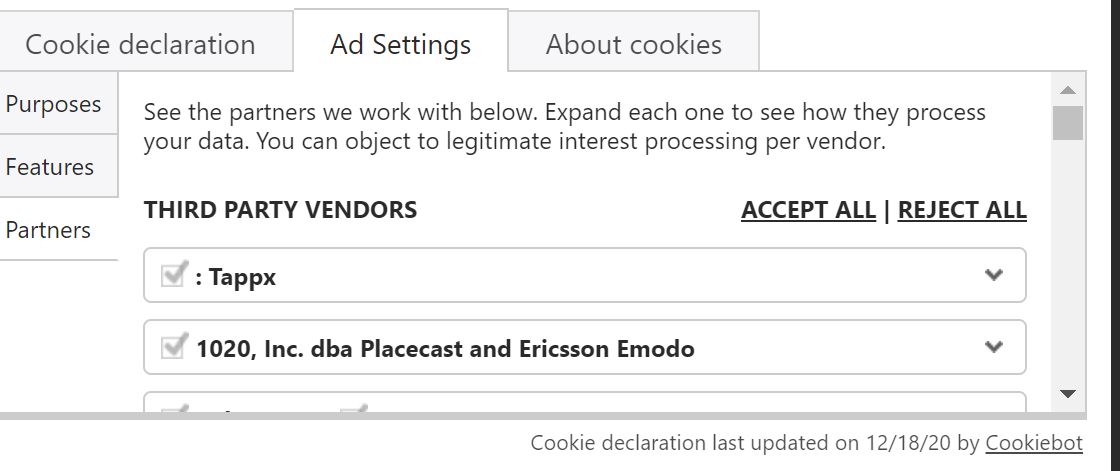
Just moments ago I visited lightpollutionmap.info to look for someone to go camping this weekend where there was as little light pollution as possible given a reasonable drive from where I’m at. I was immediately presented with a pretty comprehensive cookie banner. The FIRST thing I noticed was that I couldn’t unselect unnecessary cookies, which included over 75 “statistics” cookies.
Most of those “statistics” cookies, of course, are really third party marketing trackers. The only option presented were “Allow selection” and “Allow all cookies” which were functionally identical because you couldn’t unselect any of the types of cookies. I noticed the button for only selecting necessary cookies was still there but invisible. I clicked it, only be to presented a blank screen. See the video below showing the cookie selection options disappearing. I also noticed the ad settings options to accept or reject vendors was disabled was disabled.
Recently I had the pleasure of working with two start-ups in the AI space to help them consider privacy in their designs. Mr Young, a Canadian start-up, wants to use an intelligent agent to allow individuals to find resources available to them to improve their mental well-being. Eventus AI, a US based company, hopes to use AI to optimize the sales funnel from leads collected at events. Both recognized the potential privacy implications of their services and wanted to not only ensure compliance with legal obligations, but showcase privacy as an important aspect of their brand.
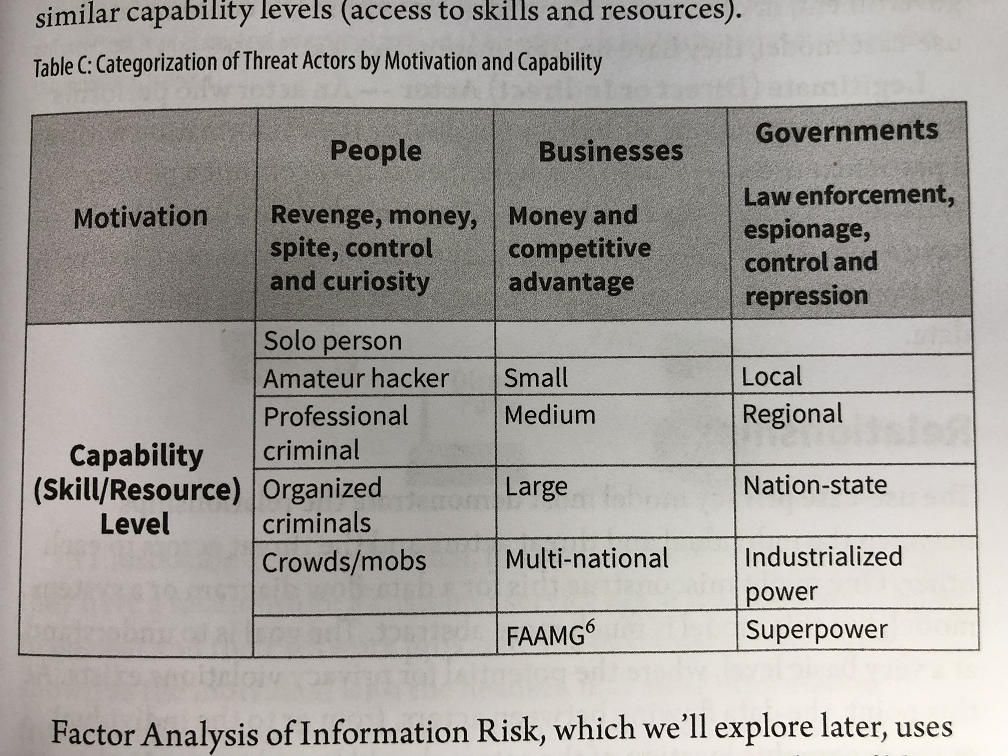
At the onset of my engagements, I had to think about how the intelligent agents driving them could threaten individuals’ privacy. In my previous work, threat actors were persons, organizations or governments, each with distinctive motives. People can be curious, seek revenge, trying to make money, or exert control. Organizations are generally driven by making money or creating competitive advantage. Governments invade privacy for law enforcement or espionage purposes. Less angelic governments may invade privacy out of desires for control or repression of their citizens.
Typically, when I think of software, it isn’t a “threat actor” in my privacy model. They don’t have independent motives. They are tools made by developers but they don’t have motives on their own. The question arises though; does AI represent a different beast? Does AI have “motives” independent of its creator? Clearly, we haven’t reached a stage where HAL 9000 refuses Dave’s command or Skynet determines humanity as a threat to its existence, but could something slightly less sentient manifest motive?
Still, I would argue that AI is not similar to other software. It can, in the sense, present a privacy threat beyond the intent of its creator. While not completely autonomous, AI does exhibit an ends justify the means approach to achieving its objective. The difference between AI and, say, a human employee, is the human can put their business objective in context of other social norms, whereas AI lacks this contextual understanding. I liken it to the dystopian analogy of robots being programmed to prevent humans from harming one another and determining the best way is to exterminate all humans. Problem solved! No more humans harming other humans. Like the genie granting a wish, they do exactly what they are told, sometimes with unintended and far-reaching consequences.
The motivation that I would ascribe to AI then is “programmatic goal-seeking.” It is not that AI seeks to invade privacy for independent purposes; rather it seeks whatever it’s been programmed to seek (such as ‘increasing engagements’). Privacy is the beautiful pasture bulldozed on AI’s straight-line path to its destination.
The question now becomes, from the perspective of a developer trying to build an AI into a system, how do you prevent privacy being a casualty of that relentless pursuit? I make no claims that my suggestion below in any way supplants all of the efforts to consider ethics in AI development (failed or successful), but rather this is the approach I take complements others. I think it gets us far along in a pragmatic and systematic way.
Before looking at tactics in the AI context (or anywhere really) there is a fundamental construct the reader must understand: the difference between data and information. Consider a photo of a person. The data is the photo – the bits, bytes, interpretations of how color should be rendered, etc. But a photo is rich with much information. It probably displays the gender of the individual, their hair color, their age, their ethnic background, perhaps their economic or social status. Even without geotagging, if the photograph has a distinctive background it could reveal the person’s location. Their subject’s hairstyle and dress and the quality and makeup of the photo might suggest the decade it was recorded. Giving over that photo to someone not only gives them the bits and the bytes but also gives them all of that rich information.
In general, for privacy by design, I use Jaap-Henk Hoepman’s strategies and tactics to reduce privacy risks. Just as they can be applied to other threat actors, I think they are equally applicable here. Returning to how to use Hoepman’s strategies against AI, consider the following example:
Your company has been tasked with designing an AI based solution to sort through thousands of applicants to find the one best suited for a job. You’re concerned the solution might adversely discriminate against candidates from ethnic minority populations. If you’re questioning whether this is even a “privacy” issue, I’d point you to the concept of Exclusion under the Solove Taxonomy. We’re (well the AI) is potentially using information, ethnicity, without knowledge and participation of the individuals, an Exclusion violation.
How then can we seek to prevent this potential privacy violation?
Two immediate tactics come to mind. These are by no means the only tactics that could or should be employed but illustrative. The first is stripping which falls under the Minimize strategy and my ARCHITECT supra-strategy. Stripping refers to removing unnecessary attributes. Here, the attribute we need to remove is ethnicity. This isn’t as simple as removing ethnicity as a data point given to the AI. Rather, returning to the distinction between data and information, we need to examine any instance where ethnicity could be inferred from data, such as a name or cultural distinctions in the way candidates my respond to certain questions. This also includes ensuring that training data doesn’t contain hidden biases in its collection.
The second tactic is auditing which falls under the Demonstrate strategy and my SUPERVISE supra-strategy. AI already employs validation data to ensure that the AI is properly goal seeking (i.e. achieving its primary purpose). Review of this validation process should be used to also continue ensuring that the AI isn’t inferring ethnicity somehow (that we failed to strip out) and using that information inappropriately as part of its goal seeking objective. If it turns out it is, then, similar to a human employee, the AI might need retraining with new, further sanitized, data.
While AI represents a new and potentially scary future, with proper design considerations and strategic systematic approaches, we reduce the potential privacy risks they would otherwise create.
fetish – ‘An excessive and irrational devotion or commitment to a particular thing.’
Basing their legislative proposal in the Fair Information Practice Principles (FIPPs), Intel looks to the past not the future of privacy. The FIPPs were developed by the OECD in the 1970’s to help harmonize international regulation on the protection of personal data. Though they have evolved and morphed, those basic principles have served as the basis for privacy frameworks, regulations and legislation world-wide. Intel’s proposal borrows heavily from the FIPPs principles: collection limitation, purpose specification, data quality, security, transparency, participation and accountability. But the FIPPs age is showing. In crafting a new law for the United States, we need to address the privacy issues for the next 50 years, not the last.
When I started working several years ago for NCR Corporation I was a bit miffed at my title of “Data Privacy Manager.” Why must I be relegated to data privacy? There is much more to privacy than data and often controls around data are merely a proxy for combating underlying privacy issues. If the true goal is to protect “privacy” (not data) then shouldn’t I be addressing those privacy issues directly? The EU’s General Data Protection Regulation similarly evidences this tension between goals and mechanism. What the regulators and enactors sought to rein in with the GDPR was abusive practices by organizations that affected people’s fundamental human rights, but they constrained themselves to the language of “data protection” as the means to do this, leading to often contorted results. The recitals to the regulation mention “rights and freedoms” no less than 35 times. Article 1 Paragraph 2 even states “This Regulation protects fundamental rights and freedoms of natural persons and in particular their right to the protection of personal data.” Clearly the goal is not to protect data for its own benefit, the goal is to protect people.
Now many people whose career revolves around data focused privacy issues may question why data protection fails at the task. Privacy concerns existed way before “data” and our information economy. Amassing data just exacerbated power imbalances that are often the root cause of privacy invasions. For those still unpersuaded whether “data protection” is indeed insufficient, I provide four quick examples where a data driven regulatory regime fails to address known privacy issues. They come from either end of Prof. Dan Solove’s taxonomy of privacy.
Surveillance – Though Solove classifies surveillance and interrogation under the category of Information Collection, the concern around surveillance isn’t about the information collected. The issue with surveillance is it invites behavioral changes and causes anxiety in the subject being watched. It’s not the use of the information collected that’s concerning, thought that may give rise to separate privacy issues, but rather the act and method of collection. Just the awareness and non-consent of surveillance (the unwanted perception of observation in Ryan Calo’s model) triggers the violation. No information need be collected. Consider store surveillance by security personnel where no “data” is stored. Inappropriate surveillance, such as targeting ethnic minorities, causes consequences (unease, anxiety, fear, avoiding certain normal actions that might merely invite suspicion) in the surveilled population.
Interrogation – Far from the stereotypical suspect in a darkened room with one light glaring, interrogation is about any contextually inappropriate questioning or probing for personal information. Take my favorite example of a hiring manager interviewing a female candidate and asking if she was pregnant. Inappropriate given the context of a job interview; that’s interrogation. It’s not about the answer (the “data”) or the use of the answer. The candidate needn’t answer to feel “violated” in the mere asking of the question, raising consequences of anxiety, trepidation, embarrassment or more. Again, we find the act and method of questioning is the invasion, irrespective of any data.
Intrusion – When Pokémon Go came out, fears about what information were collected about players abounded, but one privacy issue hardly on anyone’s radar was the use of churches by the game as places for the individual to train their characters. It turned out some of the churches on the list had been converted to people’s residences thus inviting players to intrude upon those resident’s tranquility and peaceful enjoyment of their homes. I defy any privacy professional to say that asking any developer about the personal data there are processing, even under the most liberal definition of personal data, would have uncovered this privacy invasion.
Decisional Interference – Interfering with private decisions strikes at the heart of personal autonomy. The classic examples are laws that affect family decisions, such as China’s one child policy or contraception in the United States. But there are many ways to interfere with individual’s decisions. Take the recent example of Cambridge Analytica. Yes, the researcher who collected the initial information shared people’s information with Cambridge Analytica and that was bad. Yes, Cambridge Analytica developed psychographic profile and that was problematic. But what really got the press, the politicians and others so upset was Cambridge Analytica’s manipulation of individuals. It was there attempt, successful or otherwise, to alter peoples’ perception and manipulate their decision to vote and for whom.
None of the above examples of privacy issues are properly covered by a FIPPs based data protection regime, without enormous contortion. They deal with interactions between persons and organizations or among person, not personal data. Some may claim, that while true, any of these invasions, at scale, must involve data, not one-off security guards. I invite readers to do a little Gedanken experiment. Imagine a web interface with a series of questions, each reliant on the previous answers. Are you a vegetarian? No? What is your favorite meat, chicken, fish or beef? Etc. I may not store your answer (no “data” collection) but ultimately the questioning leads you to one specific page where I offer you a product or service based on your specific selection, perhaps discriminatory pricing based on the selection. Here user interface design essentially captures and profiles users but without that pesky data collecting that would invite scrutiny from the privacy office. I’m not saying some companies might be advanced enough in their thinking, but in my years of practice most privacy assessments begin with “what personal data are you collecting?”
Now, I’ll admit I haven’t spent a time to develop a regulatory proposal but I’d at least suggest looking at Woody Hartzog’s Privacy’s Blueprint for one possible path to follow. Hartzog’s notions of obscurity, trust and autonomy as guiding privacy goals encapsulate more than a data centric world. But Hartzog doesn’t just leave these goals sitting out there with no way to accomplish them. He presents two controls that would help: signaling and increasing transaction costs. Hartzog’s proposal for signaling is that in determining the relationship between individuals and organizations and the potential for unfairness and asymmetries (in information and power), judges should look not to the legalese of the privacy notice, terms and conditions or contracts but the entirety of the interaction and interfaces. This would do more to determine whether a reasonable user fully understood the context of their interactions.
Hartzog’s other control, transaction costs, goes into making it more expensive for organization to commit privacy violations. One prominent example of legislation that increases transaction costs is the US TPCA which bans robocalls. Robocalling technology significantly decreases the cost of calling thousands or millions of households. The TCPA doesn’t ban solicitation, but it significantly increases the costs to solicitors by requiring a paid human caller to make the call. In this way, it reduces the incidents of intrusion. Similarly, the GDPR’s ban on automated decision making increases the transaction costs by requiring human intervention. This significantly reduces the scale and speed at which a company can commit privacy violations and the size of the population affected. Many would counter, and in fact many commenters on any legislative proposal, are concerned about the effect on innovation and small companies. True, that increasing transaction costs, in the way that the TCPA does, will increase costs for small firms. That is, after all, the purpose of increasing transaction costs, but the counter-argument is do you want a two-person firm in a garage somewhere adversely affecting the privacy of millions of individuals? Would you want a small firm without any engineers thinking about safety building a bridge over which thousands of commuters traveled daily? One could argue the same for Facebook, they’ve made it so efficient to connect billions of individuals they simply don’t have the resources to deal with the scale of the problems they’ve created.
The one area where I agree with the Intel proposal is about FTC enforcement. As our de-facto privacy enforcer it already has institutional knowledge to build on, but their enforcement needs real teeth not ineffectual consent decrees. When companies analyze compliance risk if the impact of non-compliance is cost comparable to the cost of compliance, the they are incentivized to reduce the likelihood of getting caught, not actually get in compliance with the regulation. The fine (impact) multiplied by the likelihood of getting fined must exceed the cost of compliance to drive compliance. This is what, at least in theory, the GDPR 4% seeks to accomplish. Criminal sanctions on individual actors, if enforced, may have similar results.
There are other problems with the FIPPs. They mandate controls without grounding in the ultimate effectiveness of those controls. I can easily technically comply with the FIPPs without manifesting improving privacy. Mandating transparency (openness in the Intel proposal) without judicial ability to consider the entirety of the user experience and expectation only yields lengthy privacy notices. Even shortened notices provide less than information about what’s going on than user’s reliance on the interactions with the company.
In high school, I participated in a mock constitution exercise where we were supposed to develop a new constitution for a new society. Unfortunately, we failed and lost the competition. Our new constitution was merely the US Constitution with a few extra amendments. As others have said we don’t need GDPR-light, we need something unique to the US. I don’t claim Hartzog’s model is the total solution, but rather than looking at the FIPPs, Intel and others proposing legislation should be looking forward for solutions for the future, not the past.
In the early years of the aught decade, Dan Solove, then assistant professor of law at Seton Hall Law School presaged that the new paradigm for privacy in the Internet age wasn’t George Orwell’s 1984 but rather Franz Kafka’s The Trial. In the book, the protagonist is subject to a secret trial in which he knows not the charges against him or the evidence used. He is not allowed to participate in the proceedings or dispute the evidence. In the end, the character is executed having never learned what the charges were. A few years later when Professor Solove developed his taxonomy of privacy, which categorized cognizable privacy violations, this form of privacy violation became known as Exclusion: the use of information about an individual without the individual’s knowledge or ability to participate. Solove’s taxonomy encompasses 17 distinct privacy violations spanning four broad categories: information collection, information processing, information dissemination and the non-information privacy issues in invasion. Exclusion is a particularly pernicious violation because it combines two fundamental forces that underlie many issues around privacy, namely imbalance in information and imbalance in power between the organization and the individual. In The Trial, the government is the perpetrator of this type of violation. Historically, government actors is where one mostly find this because government’s power monopoly prevents individual choice and the impact, such as loss of liberty, can be devastating. The unfairness of exclusion was crucial in criticisms of the US government’s no-fly list, which contained names of individuals who didn’t know they were on the list, even once known were unable to know or dispute the information used against them. Concern over exclusion also underpins the original formation of the Fair Information Practices (which was primarily aimed at government databases in the 1970s) to prevent secret databases to which individual couldn’t dispute inaccuracies. In the commercial realm, these concepts first took hold in credit reporting industry and the Fair Credit Reporting Act’s requirement for transparency and a dispute mechanism.
I’m a heavy user of Professor Solove’s taxonomy in my privacy by design training because it help participants categorize different types of privacy violations. It highlights, for most participants, that insecurity of data (which seems to be almost a fetishistic focus for many) is really only the tip of the privacy iceberg. I like to joke in my training that I’ve had every single privacy violation foisted on me in some fashion or another. Using anecdotes helps my students relate to the violations in a way that defining and explaining doesn’t. Personal stories convey even more than sensational news stories can. In one instance, I talk about how a cashier at fast food restaurant identified my then girlfriend to send her a Facebook friend request. I show students an Asian dating website where my picture was appropriated in advertising. Exclusion really hits home when I ask students if they’ve ever been put on hold and told their call will be answered by the next available operator. I discuss how some companies use secret profiles of their “problem” customers to constantly kick them to the back of the queue without the customer being able to know or dispute this status.
My most recent example comes from Amazon and is detailed below.
Last month I was traveling in Europe to attend a few privacy related events and conduct some training for Deloitte Romania. In Bucharest, I taught a CIPT course as well as my Privacy by Design class, relabeled Data Protection by Design for the EU audience. While in Romania I attempted to place an order on Amazon for an electronic gift card. Apparently this raised red flags within Amazon’s systems (an electronic gift card ordered by an American consumer but from Romania, which they probably inferred from my IP address). The order was canceled. Amazon also blocked access to my account for 5 hours.
After 5 hours, I followed the instructions, which included resetting my password. I was back in and figuring it was safe since I re-authenticated my access to my email, re-placed my order . Of course, it wasn’t. Amazon repeated it’s effort but this time required that I call to reinstate my account.
I called Amazon, spoke with a customer service agent and after answering quite a few questions (like how long I had had my Amazon account, whether I had any linked devices, etc.), my account access was reinstated and I was able to reset my password and log in. I decided NOT to try and replace my order until I returned to the US the follow week, which I did. At this point my order went through and I thought everything was behind me. I even subsequently ordered Woody Hartzog’s new book Privacy’s Blueprint, without issue. [Side note, excellent book, highly recommended, just don’t order it from Amazon ;-)]
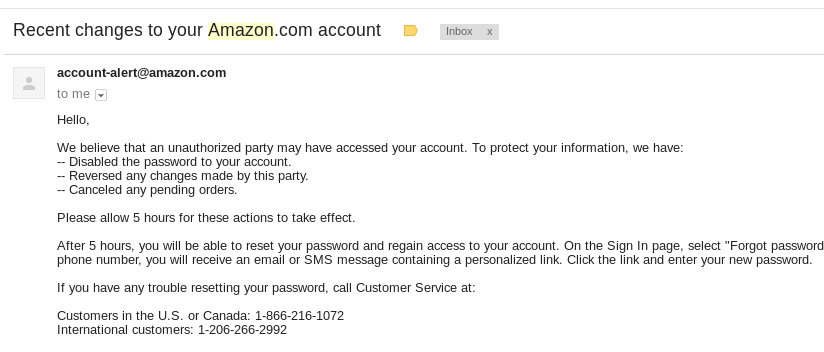
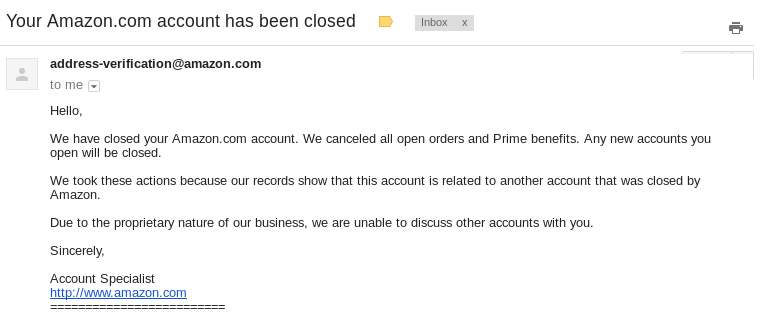
About two weeks later I’m in D.C. attending the Privacy Law Scholar’s Conference and ordered a present for a friend off their wish-list. BAM! My account was again shutdown. I didn’t realize it, since I was off doing actual work, but when I tried to check the status of the order I realized that they had shut my account down again. I called customer service but the best they could offer was to submit an email to the “Account Specialist” team. At 1:30 AM later than morning I received the following email:
Thank you for letting us know about the unauthorized activity on your Amazon.com account. For your security, the credit card information stored on your Amazon.com account cannot be accessed via our website. Your full credit card number is also not displayed in your account.
Due to this activity, your Amazon.com account has been closed and all open orders have been canceled. To continue shopping with Amazon.com, we ask that you open a new Amazon account. Your order history and other features such as Wishlists cannot be transferred to your new account.
Are you really sorry for the inconvenience this has caused, Amazon?
Note the email starts out “Thank you for letting us know about unauthorized activity.” I quickly responded that there was no authorized activity (and I certainly didn’t let them know). Oddly enough there was another email at 9:30AM that morning (AFTER the account closure) suggesting I needed to call to reset my password again. I did call but the customer service agent was only able to offer to send another email to the Account Specialist team.
Frustrated at this point, and not wanting my friend’s present further delayed, I dutifully followed the instructions about using another Amazon account, after all Amazon specifically told me that “To continue shopping with Amazon.com, we ask that you open a new Amazon account.” I went into my business account which I had previously used to host AWS instances for various business projects.However, my attempt to complete my order was similarly thwarted. I initially received an email to confirm my billing address, which I quickly replied. I was then presented with this sternly worded email:
“Any new accounts you open will be closed.”
So, despite having told me previously to open a new account to continue shopping, Amazon has decided they will close any account I open in the future, with no discussion of why this was occurring, no information as to what led to this decision and no opportunity to dispute or appeal it. Some faceless, nameless, bureaucratic Account Specialist had declared me persona non-grata. Assuming the Account Specialist is even a person and not a bot.
My virtual death as an Amazon customer.
Quite a few of the most recent complaints on BBB for Amazon are about inexplicable account closures. Luckily, my dependence on Amazon is negligible. Though I’ve been a customer 10 years, I wasn’t using AWS actively and canceled Prime just a few months ago because it wasn’t worth the costs. However, I could only imagine how this could have affected me. Having dinner the next day with a friend in the privacy/security industry he was shocked and concerned because he orders virtually everything off Amazon as I know many do. What if I used Kindle, would I lose all my purchases? I’d be more concerned about those who’s livelihood depended on the Amazon service. What if I was an associate and depended on Amazon referrals for this blog’s revenue? Or a reseller on Amazon? What I had had extensive use of AWS for my business? Perhaps if I was in one of these categories they would have been more circumspect in their closing my account. Perhaps I would have had another avenue to escalate, but as a regular consumer I certainly didn’t.
As for my particular circumstances, first and foremost, I’m a bit miffed that I can’t get my order history and wish-lists. I have frequently referred to my order history when doing my year end taxes as some of my purchases are business related. Also, I’ve spent years adding things to my wish-list, mostly books that I’ll probably never get around to ordering, though I have had relatives order them occasionally for birthdays in the past. There is no way for me to reconstruct this information. Account closure seems particular vindictive. Of course, I don’t know why they closed my account, so it’s hard to say. I can only guess that they suspected some sort of fraudulent activity despite all the charges to my account having always gone through and never disputed. If potential fraud is the reason, they could have suspended ordering privileges, but allowed the account to still access historical data. One problem with behemoths such as Amazon is that by providing multiple services to which people may become dependent, a problem in one area can have an out-sized impact on the individual. Segmentation of services is important in reducing risks. A problem with my personal account shouldn’t affect my business account. A problem with ordering physical products shouldn’t affect my Prime video membership or Kindle e-books. A problem with my use of the affiliate program shouldn’t affect my personal use as a shopper. Etc.
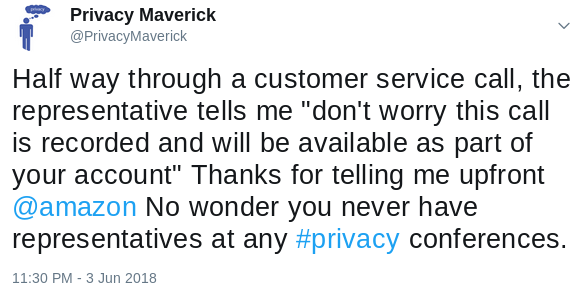
Maybe my tweet complaining that they were recording my call without informing me up front was the reason they closed my account.
Were I in the EU, I might have some additional recourse under the newly passed GDPR. Namely
Under Article 15 I could receive the personal information they have on me, including not only my wish-list and order history, but potentially whatever information was the basis for the account closure.
Under Article 16, I could potentially rectify any inaccurate data about me which may have lead to the decision to close my account.
Under Article 20, the right to data portability. While this probably doesn’t apply to my order history, since it’s arguable whether I “supplied” the information, it would apply to my wish-list, since that subjective preference data is something I supplied when I clicked “Add to my wish-list”
Under Article 21, the right not to be subject to automated decision making. More specifically: the data controller shall implement suitable measures to safeguard the data subject’s rights and freedoms and legitimate interests, at least the right to obtain human intervention on the part of the controller, to express his or her point of view and to contest the decision.
Of course, I don’t know if the account deletion determination was based on an automated decision, but I suspect in part, they have some AI making a determination at some point to suspend or restrict use of my account.
Once it’s available, I’ve been considering applying for Estonia’s digital nomad visa. If I still care at that point, when I’m in the EU, I might subject Amazon to some of these rights to which I’m not afforded as someone in the US. It’s highly likely I won’t care at that point. As I stated, my use of Amazon, unlike many associates of mine, has been limited. Maybe my account closure is a good thing as it pushes me closer to removing my reliance on the big tech firms. I’ve closed my Facebook account and haven’t used Facebook in almost 6 months (though to be transparent, I still use Instagram). I moved several years ago to a Libre 15 by Purism running PureOS (an Ubuntu Linux variant) and away from Windows, though again in full transparency, I purchased a Microsoft Surface Pro for presentations (on newegg, btw, where I’ll obviously be shopping more from now on). At least Microsoft is more in the pro-privacy camp. I’m still trying to extricate myself from Google. I purchased an iPhone (again on newegg) for the first time having been an Android user for many years. I’m still, unfortunately, on GoogleFi because I like that it works when I travel internationally. I still use Gmail for my personal email, though not for business anymore, having my own domain. One reason I still use Gmail is when I have to give my email address to someone orally, I know they aren’t going to misspell gmail.com like they might privacymaverick.com.
I’ve rallied for years against the use of PII (or Personally Identifiable Data) as unhelpful in the privacy sphere. This term is used is some US legislation and has unfortunately made its way into the vernacular of the cyber-security industry and privacy professionals. Use of the term PII is necessarily limiting and does allow organizations to see the breadth of privacy issues that may accompany non-identifying personal data. This post is meant to shed light on the nuances in different types of data. While I’ll reference definitions found in the GDPR, this post is not meant to be legislation specific.
Personal Data versus Non-personal Data
The GDPR definesPersonal Data as “means any information relating toan identified or identifiable natural person (‘data subject’); an identifiable natural person is one who can be identified, directly or indirectly, in particular by reference to an identifier such as a name, an identification number, location data, an online identifier or to one or more factors specific to the physical, physiological, genetic, mental, economic, cultural or social identity of that natural person.” The key here term in the definition is the phrase “relating to.” This broad refers to any data or information that has anything to do with a particular person, regardless of whether that data helps identify the person or that person is known. This contrast with non-personal data which has no relationship to an individual.
Personal Data: “John Smith’s eyes are blue.”
In this phrase, there are three pieces of personal data. The first is the name John which is a first name related to an individual, John Smith. The second is his last name. Finally, the third is blue eyes, which also relates to John Smith.
Anonymous Data: “People’s eyes are blue.”
No personal data is indicated in the above sentence as the data doesn’t relate to an individual, identified or identifiable. It relates to people in general.
Identified Data versus Pseudonymous Data
Much consternation has been exhibited over the concept of pseudonymized data. The GDPR provides a definition of pseudonymized: “means the processing of personal data in such a manner that the personal data can no longer be attributed to a specific data subject without the use of additional information, provided that such additional information is kept separately and is subject to technical and organisational measures to ensure that the personal data are not attributed to an identified or identifiable natural person.” The key phrase in this definition is that data can no longer be attributed to an individual without additional data. Let me break this down.
Identified Data: “John Smith’s eyes are blue.”
The same phrase we used in our example for Personal Data is identified because the individual, John Smith, is clearly identified in the statement.
Pseudonymous (Identifiable) Data: “User X’s eyes are blue.”
Here we have processed the individual’s name and replaced it with User X. In other words, its been pseudonymized. However, it is still identifiable. From the definition above, Personal Data is data relating to an identified or identifiable individual. Blue eyes are still related to an identifiable individual, User X (aka John Smith). We just don’t know who he is at the moment. Potentially we can combine information that links User X to John Smith. Where some people struggle is understanding there must be some form of separation between the use of the User X pseudonym and User X’s underlying identity. Store both in one table without any access controls and you’ve essentially pierced the veil of pseudonymity. WARNING: Here is where it can get tricky. Blue eyes are potentially identifying. If John Smith is the only user with blue eyes, it makes it much easier to identify User X as John Smith. This is huge pitfall as most attributable data is potentially re-identifying when combined with some other data.
Identifying Data versus Attributable Data
In looking at the phrase “John Smith’s eyes are blue” we can distinguish between identifying data and attributable data.
Identifying Data: “John Smith”
Without going into the debate of number of John Smiths in the world, we can consider a person’s name as fairly identifying. While John Smith isn’t necessarily uniquely identifying, a type of data, a name, can be uniquely identifying.
Attributable Data: “blue eyes”
Blue eyes is an attribution. It can be attributable to a person, in the case of our phrase “John Smith’s eyes are blue.” It can be attributable to a pseudonym: “User X’s eyes are blue.” As we’ll see below, it can also be attributed anonymously.
Anonymous Data versus Anonymized Data
GDPR doesn’t define anonymous data but in Recital 26 it says “anonymous information, namely information which does not relate to an identified or identifiable natural person or to personal data rendered anonymous in such a manner that the data subject is not or no longer identifiable.” In the first example, I distinguished Personal Data with Anonymous Data, which didn’t relate to specific individual. Now we need to consider the scenario where we have clearly Personal Data which we anonymize (or render anonymous in such a manner that the data subject is not or no longer identifiable).
Anonymous Data: “People’s eyes are blue.”
For this statement, we were never talking about a specific individual, we’re making a generalized statement about people and an attributed shared by people.
Anonymized Data: “User’s eyes are blue.”
For this statement, we took Identified Data (“John Smith’s eyes are blue”) and processed in a way that is potentially anonymous. We’ve now returned to the conundrum presented with Pseudonymous data. Specifically, if John Smith is the only user with blue eyes, then this is NOT anonymous. Even if John Smith is a one of a handful of users with blue eyes, the degree of anonymity is fairly low. This is the concept of k-anonymity, whereby a particular individual is indistinguishable from k-1 other individuals in the data set. However, even this may not given sufficient anonymization guarantees. Consider a medical dataset of names, ethnicities and heart condition. A hospital releases an anonymized list of heart conditions (3 people with heart failure, 2 without). Someone with outside knowledge (that those of Japanese descent rarely have heart failure and the names of patients) could make a fairly accurate guess as to which patients had heart failure and which did not. This revelation brought about the concept of l-diversity in anonymized data. The point here is that unlike Anonymous Data which never related to a specific individual, Anonymized Data (and Pseudonymized Data) should be carefully examined for potential re-identification. Anonymizing data is a potential minefield.
White the idea was fresh in my mind, I wanted to take a moment to replay some of the concepts we touch upon for a wider audience and talk about the case study we used in more detail than the forum allowed. First off, what did we mean by bots? I don’t claim this is a definitive definition but we took the term, in this context, to mean two things:
Some form of human like interface. This doesn’t mean they have to the realism of Replicants in Blade Runner, but some mannerisms in which a person might mistake the bot for another person. This goes back to the days, as Elena pointed out, of Alan Turing and his Turing test, years before any computer could even think about passing. (“I see what you did there.”). The human like interface potentially has an interesting property, are people more likely to let their guard down and share sensitive information if they think they are talking to another person? I don’t know the answer to that and their may be some academic research on that point. If their isn’t I submit that it would make for some interesting research.
The second is the ability to learn and be situationally aware. Again, this doesn’t require the super sophistication of IBM’s Watson but any ability to adapt to changing inputs from the person with whom it is interacting. This is key, like the above, to giving the illusion a person is interacting with another person. By counter example, Tinder is littered with “bots” that recite scripts with limited, if any, ability to respond to interaction.
Taxonomy of Risk
Now that we have a definition, what are some of the heightened risks associated with these unique characteristics of a bot that, say, a website doesn’t have? I use Dan Solove’s Taxonomy of Privacy as my goto risk framework. Under the taxonomy I see 5 heightened risks:
Interrogation (questioning or probing of personal information): In order to be situationally aware, to “learn” more, a bot may ask questions of someone. Those questions could go too far. While humans have developed social filters, which allows us to withhold inappropriate questions, a bot lacking a moral or social compass could ask questions which make the person uncomfortable or is invasive. My classic example of interrogation is an interview where the interviewer asks the candidate if they are pregnant or planning to become pregnant. Totally inappropriate in a job interview. One could imagine a front like recruitment bot smart enough to know that pregnancy may impact immediate job attendance of a new hire but not smart enough to know that it’s inappropriate to ask that question (and certainly illegal in the U.S. to use pregnancy as a discriminatory criteria in hiring).
Aggregation (combining of various piece of personal information): Just as not all questions are interrogations, not all aggregation of data creates a privacy issue. It is when data is combined in new and unexpected ways, resulting in information disclosure than the individual didn’t want to disclose. Anyone could reasonably assume Target is aggregating sales data to stock merchandise and make broad decisions about marketing, but the ability to discern pregnancy of a teenager from non-baby related purchased was unexpected, and uninvited. For a pizza ordering bot, consider the difference between knowing my last order was a vegetable pizza and discerning that I’m a vegetarian (something I didn’t disclose) because when I order for one its always vegetable but if I order for more than one, it includes meat dishes.
Identification (linking of information to a particular individual): There may be perfectly legitimate reasons a bot would need to identify a person (to access that person’s bank account for instance) but identification as an issue comes into play when its the perception of the individual that they would remain anonymous or at the very least pseudonymous. If I’m interacting with a bot as StarLord1999 and all the sudden it calls me by the name Jason, I’m going to be quite perturbed.
Exclusion (failing to let an individual know about the information that others have about her and participate in its handling or use): As with aggregation, a situationally aware bot, pulling information from various sources may alter its interaction in a way that excludes the individual from some service without the individual understanding why and based on data the individual doesn’t know it has. For instance, imagine a mortgage loan bot, that pulls demographic information based on a user’s current address, and steers them towards less favorable loan products. That practice sounds a lot like red-lining and if it has discriminatory effects, could be illegal in the U.S.
Decisional Interference (intruding into an individual’s decision making regarding her privacy affairs): The classic example I use for decisional interference is China’s historic one-child policy which interferes with a family’s decision making on their family make-up, namely how many children to have. So you ask, how can a bot have the same effect? Note the law is only influential, albeit in a very strong way. A family can still physically have multiple children, hide those children or take other steps to disobey the law, but the law is still going to have a manipulatory effect on the decision making. A bot, because if it’s human interface, and advanced learning and situational knowledge, can be used to psychologically manipulate people. If the bot knows someone is psychologically prone to a particular type of argument style (say appealing to emotion) it can use that and information at it’s disposal to subtly persuade you towards a certain decision. This is a form of decisional interference.
Architecture and Policy
I’m not going to go into a detailed analysis of how to mitigate these issues, but I’ll touch on two thoughts: first, architectural design and second, public policy analysis. Privacy friendly architecture can be analyzed along two axes, identifiability and centralization. The more identified and more centralized the design, the less privacy friendly it is. It should be obvious that reducing identifiability reduces the risk of identification and aggregation (because you can’t aggregate external personal data from unidentified individuals) so I’ll focus here on centralization. Most people would mistakenly think of bots as being run by a centralized server, but this is far from the case. The Replicants in Blade Runner or “autonomous” cars are both prominent examples of bots which are decentralized. In fact, it should be glaringly apparent that a self-driving car being operated by a server in some warehouse introduces unnecessary safety risks. The latency of the communication, potential for command injections at the server or network layer, and potential for service interruption are unacceptable. The car must be able to make decisions immediately, without delay or risk of failure. Now decentralization doesn’t help with many of the bot specific issues outlined above, but it does help with other more generic privacy issues, such as insecurity, secondary use and others.
Public policy analysis is something I wanted to introduce with my case study during the interactive portion of the session at the Privacy and Security Forum. The case study I present was as follows:
Kik is a popular platform for developing Bots. https://bots.kik.com/#/ Kik is a mobile chat application used by 300 million people worldwide and an estimated 40% of US teens at one time or another have used the application. The National Suicide Prevention Hotline, recognizing that most teens don’t use telephones wants to interact with them in services they use. The Hotline wants to create a bot to interact with those teens and suggest helpful resources. Where the bot recognizes a significant risk of suicide rather than just casual inquiries or people trolling the service, the interactions will first be monitored by a human who can then intervene in place of the bot, if necessary.
I’ll highlight one issue, decisional interference, to show why it’s not a black and white analysis. Here, one of the objectives of the service and the bot, is to prevent suicide. As a matter of public policy, we’ve decided that suicide is a bad outcome and we want to help people who are depressed and potentially suicidal get the help they need. We want to interfere with this decision. Our bot must be carefully designed to promote this outcome. We don’t want the bot to develop in a way that doesn’t reflect this. You could imagine a sophisticated enough bot going awry and actually encouraging callers to commit suicide. The point is, we’ve done that public policy analysis and determined what the socially acceptable outcome is. Many times organizations have not thought through what decisions might be manipulated by the software they create and what the public policy is that should guide they way the influence those decisions. Technology is not neutral. Whether it’s is decisional interference or exclusion or any of the other numerous privacy issues, thoughtful analysis must precede design decisions.
As many of you probably know, the Lesser Antilles in the Caribbean were battered this week by Hurricane Irma, one of, if not, the most powerful storms to hit the Caribbean. Barbuda was essentially annihilated (90% of building damaged or destroyed). Anguilla, a country of only 11,000, hasn’t fared too well either.
What some, but not all, in the Financial Cryptography/crypto-currency community may not know is that Anguilla was home to the first and several subsequent International Financial Cryptography Conferences from 1997. The association, IFCA, still bears that legacy with the TLD of .ai, ifca.ai. The paper presented at IFCA conference and the discussions held by many of its participants paved the ground for Tor, Bitcoin and the crypto-currency revolution. Eventually, the conference had grown to big for this tiny island.
More directly, two of the founders of that conference, Bob Hettinga and Vince Cate, currently live on Anguilla. While they have since separated from IFCA, their early evangelism was instrumental in the robust, thriving and important work developed at the conference throughout the years. Bob and Vince were both directly affected by the hurricane, though not their spirit. Here is a quote from Bob about the aftermath:
Have a big wide racing stripe of missing aluminum from front to back. Sheets of water indoors when it rains. Gonna tarp it over tomorrow though. Sort of a rear vent across the back of the great room. See the videos. Blew out three steel accordion shutters covering three sliding glass doors. 200mph winds? No plywood on the island, much less aluminum.
Airport has no tower anymore. SXM airport had its brand new terminal demolished. Royal Navy tried to land at the commercial pier but the way was blocked. Rum sodomy and the lash. 🙂
We need money of course, blew a bunch prepping, etc. No reserves to speak of even then. Gotta pay people to do a bunch of stuff, but the ATMs are down so people are just doing shit anyway. Works in our favor except to buy actual stuff. We hadda a little cash stashed in the house and paid about half of that boarding up three of the six demolished sliding glass doors. Tomorrow we’ll put the MICR numbers off one of [Mrs RAH’s] checks here, so you can wire us money if you want. Heh. It still might be weeks before we get it. Or days. Just no idea right now.
If we can get the materials replacing the aluminum on the roof can be done in a couple days. Getting it here under normal circumstances would take weeks.
Certainly months now.
Then we have to rip out and replace all the Sheetrock in the house, basically all the closets and bathrooms and the inner bedroom walls. Again days to fix, months to do.
All the gas pumps on the island were flattened. Literally blown away. That makes thing interesting. A couple grocery stores are open, but who knows how long there inventories will hold up.
See “Royal Navy” above.
Both cisterns fine. 38000 gallons total. Full. Wind ripped off the gutters so no discernible salt in the water. And little floating litter on top. We’ve got water, and we can pull buckets out of the cisterns until the cows come home. I’d been looking at building a hand pump out of PVC and check valves, and now I have some incentive.
Car needs brake work. Threw the error codes the day after the storm. Supposed to park it and have the shop come and get it. Heh. No shop anymore. No money so it works out. 🙂 Car exists to charge the smartphones at the moment. Full tank. Life is good
See the rain from inside Bob’s house during the Hurricane.
I’m making this post to request that the community support Bob, Vince and the island of Anguilla. We can’t help the entire Caribbean but we can donate to efforts to support them and our adoptive island of Anguilla.
For donations to support the island of Anguilla, please consider donating to the Help Anguilla Rebuild Now fund or individual recipients on this page
To help Bob or Vince, please contact them directly (or you can contact me). I will update this page with funding options as I’m made aware of them.
The whole employment market seems FUBAR (look it up if you don’t know). Not only am I constantly inundated with spam and calls telling me about a great new Sharepoint developer a staffing agency can place with me, recruiters send me desperately mismatched job opportunities. One particular one recently came across my email for a “Security Analyst” role. What struck me wasn’t the badly formatted main part of the message but the hilarity of the footers.
First was this:
The information transmitted in this email is intended solely for the individual or entity to which it is addressed and may contain confidential and/or privileged material. If you are not the intended recipient, be aware that any disclosure, copying, distribution or use of the contents of this transmission is prohibited. If you have received this transmission in error, please contact the sender and delete the material from your system.
The email “may” contain confidential information? I’m “prohibited” from disclosing the contents of the email? By what law, regulation, contract, theory or act of God am I prohibited? This type of language is reminiscent of the blind leading the naked. It’s the same silliness that I get sometimes when someone explains to me I have to answer their question because “It’s the law!” Really? What law? Where did you go to law school? Often time, it a refrain people use to make someone else compliant with their needs and wishes. If the recipient is as ignorant of the law as the sender, then compliance is assured.
The second part of the footer was even funnier:
Note: We respect your Online Privacy. This is not an unsolicited mail. Under Bill s.1618 Title III passed by the 105th U.S. Congress this mail cannot be considered Spam as long as we include Contact information and a method to be removed from our mailing list. If you are not interested in receiving our e-mails then please enter “Please Remove” in the subject line and mention all the e-mail addresses to be removed, including any e-mail addresses which might be diverting the e-mails to you. We sincerely apologize for any inconvenience.
Let’s tally up the errors in this, shall we?
We respect your Online Privacy. Really? If you respected my privacy, you wouldn’t be spamming me with unsolicited messages, regardless of the law.
This is not an unsolicited mail. I didn’t solicit it, therefore it is unsolicited. You might be able to argue (though wrongly) that it doesn’t meet the definition of spam or isn’t illegal, but you can’t truthfully say it is not unsolicited.
Under Bill s.1618 Title III passed by the 105th U.S. Congress this mail cannot be considered Spam as long as we include Contact information and a method to be removed from our mailing list. Somewhat technically true. Under that bill passed by the Senate in 1998, an “unsolicited commercial electronic mail message” must contain specific contact information and must stop further messages upon a reply that includes remove in the subject line. Several problems though. First, doing so doesn’t make it not spam (in fact the bill didn’t define spam) but rather makes it illegal if you don’t do so. Second, this bill, though it passed the Senate, never became law. While the email I received never claimed it was the law, the implication is clearly there. On a side note, they failed to include a physical address as required by this “bill.”
If you are not interested in receiving our e-mails then please enter “Please Remove” in the subject line and mention all the e-mail addresses to be removed, including any e-mail addresses which might be diverting the e-mails to you. Wait, I have to include ALL e-mail address that might be diverting email to me? I have like 50 of those. I’m not sending you a list of all my email addresses. Just remove the one you sent me this message from!
We sincerely apologize for any inconvenience. No you don’t. You can’t be remorseful in advance. Apology not accepted.
[Twitter rarely affords me the opportunity for a full discussion. I prevent the following in clarification of a recent tweet.]
A recent promoted ad campaign called Purple Purse on Twitter caught my attention. Notably, the ad uses a purported hidden camera footage of individuals finding a purse left in a cab. In the purse, the phone rings and the cab rider, after routing through the purse and then the phone uncover evidence of domestic (financial) abuse.
First off, I want to say that domestic abuse is a hideous and far too common crime in the world today. I can’t count the number of times I’ve personally witnessed it and been essentially helpless to do anything. Two recent incidents come to light. Once, while sitting on the patio (alone) at a restaurant at lunch, I witnessed a young man following a woman (within inches). While not physically accosting her, he was certainly intimidating her and speaking to her in a manner to exert control over her. I couldn’t exactly tell what he was saying but based on their interaction they did not appear to be strangers.
The second incident took place one night while staying at a friend’s apartment. I could hear upstairs, the male occupant verbally and physically assaulting his girlfriend. I was set to call the police but my friends said she had done so on several occasions with no positive outcome. I withheld calling, principally out of concern for my friend as it was clear, hers was the only apartment which could hear the altercation. I didn’t want my friend hurt based on my calling the police on this obviously violent individual.
On another occasion, I did call the police years ago when I heard my pregnant neighbor being beaten by her then boyfriend. He left before they arrived, but they later arrested him.
Privacy has long been a shield to protect domestic abusers against government invasions. In general, the right to make familial decisions and be free from government interference, is a hallmark of federal privacy law. It’s the basis of the Roe v. Wade decision and Griswold v. Connecticut whereupon the right to privacy is a right against government intrusion in the sanctity of family decisions. Unfortunately, in a historically patriarchal society, the same argument supported a man’s right to discipline his wife. That view, fortunately, has fallen out of favor, at least within the law in the U.S.
Financial dependence goes hand in hand with domestic abuse. Controlling the purse strings is one of the strongest ways that domestic abusers control their victims. So it’s perfectly appropriate for the group behind Purple Purse to focus on “financial” domestic abuse as a means of uncovering deeper problems. This is one of the reasons that the financial industry must find ways to support “financial privacy” not just in confidentiality of financial transactions but censorship resistant financial tools. It isn’t just the government that is prone to censor people’s financial choices.
Lock screen from my personal phone indicating a number to contact if found.
On it’s face, it appears that Purple Purse is encouraging people to invade one type of privacy (confidentiality) to discover another (financial privacy), or at the least offset a social evil (“domestic abuse”). One could make the argument, that if a victim needed to covertly disclose her predicament, without alerting her abuser, though this would be a mechanism to do so. Most people with an interest in their own privacy lock their phone, even with a simple 4 digit pin code. In the words of courts, locking one’s phone is a manifestation of a subjective expectation of privacy in the phone. Locking one’s phone is something which an outsider can view as an affirmative act which says “Hey this is private, keep out.” To further the legal analysis, locking one’s phone is a manifestation which society is willing to objectively recognize.
I’m not making the argument that one might not have a subjective expectation of privacy in a lost, but unlocked phone, but certainly the case is stronger if the phone is locked. A left unlocked phone could be, as the Purple Purse might be suggesting, an effort by a victim to seek help.