
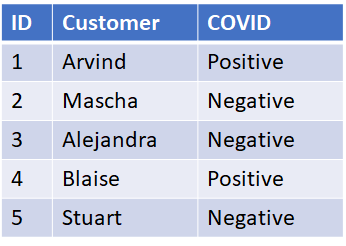
One of the potential downsides of relational data is the ease at which data can be related in both directions. A simple search of the table below will reveal not only if a known customer has COVID but a list of all COVID positive customers.
Supposed instead, you want to be able to determine if a customer has COVID but not easily obtain a list of all customers who have COVID. How might you do that? This can be accomplished using one-way functions (hashes).. By hashing the customer’s name (shown as H(name) function) and replacing that in the customer field, we no longer can get a list of customer’s with COVID. A simple SQL query will get the customer’s COVID status from their name: SELECT Covid from TABLE where Customer = hash(customer_name). The inverse, however, won’t get me the list of customers with COVID but a list of hashes: select customer from TABLE where COVID =”Positive”.
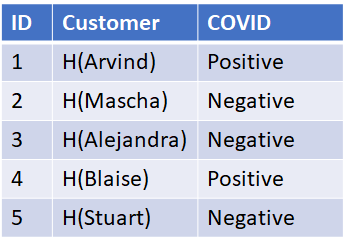
Now hashes are one way functions, meaning it’s very difficult to determine x, given H(x). However, because of the very few values of customer’s name, it’s easy to compute what’s called a rainbow table, that is a table of all possible hash values. We can then lookup the hash in the rainbow table and obtain the customer’s name for those customers that have COVID. The table below assumes we know all the names of customers, an attacker may not, but names are fairly common and even if we created our rainbow table with six thousand different common first names, that’s fairly trivial to compute.

We address this with a concept called salting, which is adding a random value to the Name before hashing it, i.e. Customer = H(Name+Salt). One problem though we can’t use the same salt for every customer or an attacker could precompute a rainbow table just adding the salt to each name before calculating the hash. We also need the salt BEFORE we do the hash. Now customer’s can’t be expected to remember the salt before looking it up, but we can give them an account number, which we can relate to the salt. A customer, wanting to look up their COVID status, enters their account number and name. The system retrieves the salt using the account number and hashes the name to determine the customer and look up their COVID status. [Note, salts should be incremented with each access to prevent replay attacks but that’s beyond the scope of this blog].
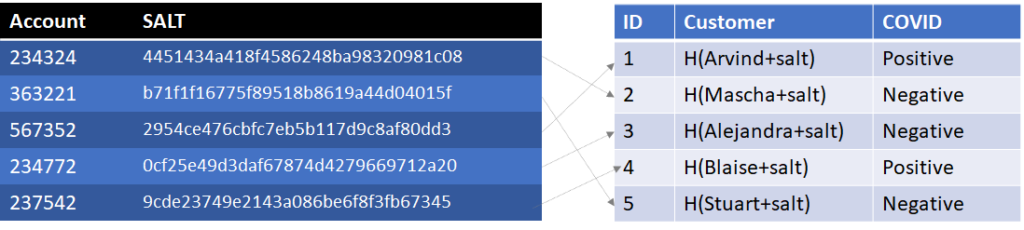
Now an attacker wanting to identify all known COVID cases would need to hash all the possible customer names against all the possible salts. Padding the salt table with hundreds of thousands of random account numbers could increase the number of computations necessary for the attacker. In fact, you could prefill the account table with a million rows and a million salts and randomly assign account numbers to customers. Even if two customers got the same account number, they aren’t going to get the same Customer value unless they have the same name, H(name+salt). This also benefits us because if we have two people with the same name, they could be given different account numbers and distinct COVID statuses.
In order to create a rainbow table now an attacker must hash six thousand names with a million account numbers, or 109 rows. Not impossible but starting to slow them down.
I’m going to make it even a little bit harder. Right now, we can still use the COVID table to identify how many people are COVID positive or negative. This is especially problematic if each and every customer has the same status. We can do a little encryption and steganography to hide the information. First, for each record we can generate a random 64 byte value (say 787683b51cf3b49886fce82dc34a51a2 in Hexadecimal). If we need to encode a negative result, we ensure that value has the least significant bit of 0. If we need to encode a positive result, we ensure that value has the least significant bit of 1 (i.e. 787683b51cf3b49886fce82dc34a51a3). Note the change in the last digit from 2 to 3, changing the least significant bit and the COVID status. That value is then encrypted using a symmetric cypher (such as AES) without padding or authentication to verify the accuracy of the data. We can use part of the SALT as the encryption key (bolded in the table below)
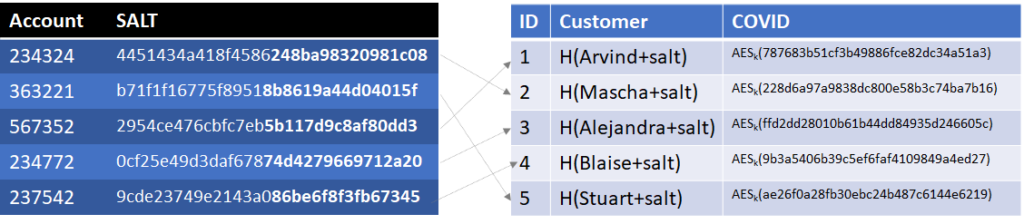
Now, an attacker can’t search the COVID table to identify how many customers have COVID. Additionally, because we used an encryption algorithm without any validation, any of the values in the COVID column will decrypt with any of the encryption keys in the account table, just with erroneous least significant bits, thus not disclosing anyone’s COVID status at all. If we used a decryption algorithm with padding or authentication, it would provide a quicker backdoor for connecting records in the account table with records in the COVID table.
One more step to slow a potential attacker down is to iterate the hashing, in other words compute H( H( H( H( …. H(name+salt))))), say 100,000 times. While slowing down lookups slightly, it significantly increases the computation of a rainbow table for an attacker, who now must compute 100,000 x 109 hashes. Increasing the number of values in the account table, increasing the potential values for name (such as using given name and surname), and increasing the number of iterations will all serve to slow an attacker down.
The concept described above is sometimes called a translucent database, such that someone who has full access to the data (a database engineer) still can’t interpret it, but with a little extra knowledge (account number and name), a customer can still retrieve their COVID status.